
Data Scientist: un métier en plein essor
En 2018, le Harvard Business Review a désigné le métier de Data Scientist comme le métier le plus “hot” du 21e siècle, mettant en évidence l’importance et l’influence des données sur le marché mondial. Cependant, ce domaine n’a pas encore atteint tout son potentiel et il existe encore de nombreuses idées fausses sur ce qu’est réellement le travail d’un Data Scientist. Pour de nombreuses personnes, cela reste un domaine “technique vague”, avec des capacités de mise en œuvre de produits ou services. Ces malentendus peuvent entraîner une mauvaise utilisation des ressources. Reculons donc d’un pas pour avoir une meilleure compréhension du métier de Data Scientist et découvrir comment s’engager dans cette voie.
Le rôle d’un Data Scientist
Un Data Scientist est une personne qui analyse, organise et raconte des histoires à partir de données, qu’elles soient structurées ou non. Leur travail implique une combinaison de connaissances en informatique, en statistiques et en mathématiques. Ils sont responsables de l’analyse, du traitement et de la modélisation des données, puis interprètent les résultats pour élaborer des plans d’action pour l’équipe et l’entreprise.
En d’autres termes, le travail d’un Data Scientist consiste à travailler avec des données pour obtenir des informations analytiques. Ils communiquent ces découvertes et informations à des parties prenantes telles que les hauts dirigeants, les gestionnaires et les clients. Ainsi, les entreprises peuvent bénéficier directement de la prise de décision la plus éclairée pour stimuler leur croissance et leurs bénéfices (en fonction du contexte industriel).
Au Vietnam, le secteur des technologies de l’information connaît une croissance potentielle dans le domaine de la Science des données. De plus en plus d’entreprises s’intéressent à ce domaine et sont prêtes à investir dans la recherche et le développement. Il est donc juste de dire que le métier de Data Scientist est l’un des plus recherchés sur le marché vietnamien. Mais le connaissez-vous vraiment ?
Les différentes fonctions d’un Data Scientist
Qu’est-ce que la Science des données ?

L’objectif du département Science des données est d’aider les différentes parties de l’entreprise à prendre de meilleures décisions basées sur les données. La Science des données joue donc un rôle de soutien (similaire aux TI), permettant à l’organisation de fonctionner de manière plus efficace et de générer de la valeur plus rapidement grâce à de meilleures décisions.
Le processus de travail du département Science des données comprend des jalons importants (nuages), des étapes (lignes en pointillés) et des étapes (boîtes grises). Le processus commence par un problème spécifique (Jalon 1) – l’entreprise priorisera ce problème pour l’équipe de science des données, qui commencera alors le processus de gestion de projet.
Le cycle de la Science des données comprend 3 étapes :
- Préparation – Les données sont collectées et nettoyées. Cela prend généralement beaucoup de temps, car la plupart des données sont bruyantes et nécessitent des étapes pour améliorer leur qualité et les convertir en un format que les machines peuvent comprendre et lire.
- Expérimentation – C’est là que les hypothèses sont formulées, les données sont visualisées et les modèles sont créés. Cela prend moins de temps que la phase de préparation.
- Mise en œuvre – Les résultats des rapports sont enregistrés sous forme de documents, de diaporamas pour les managers. Une fois que les managers ont validé les décisions, elles sont transmises pour être mises en œuvre.
À la fin du processus, cette phase de mise en œuvre sera le moment où une nouvelle Valeur métier est créée pour l’entreprise.
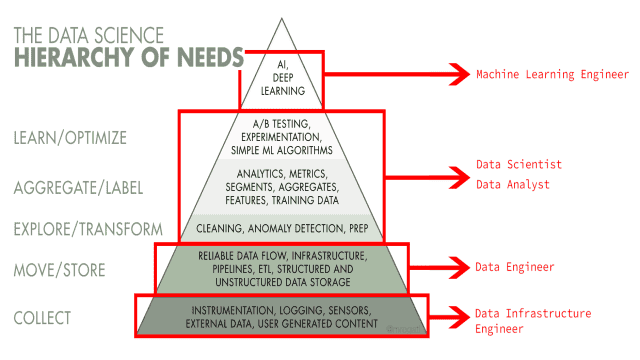
Différence entre un Data Scientist, un Data Engineer et un Data Analyst
Selon l’échelle et le modèle de l’entreprise, chaque poste dans chaque organisation aura des rôles et des responsabilités différents. Cependant, voici un modèle global de distinction entre le trio de Data :
- Data Scientist : analyse, teste, compile, optimise les données et les présente à l’entreprise. Les Data Scientist ont généralement 4 tâches principales : analyser, tester, créer et présenter les conclusions aux équipes.
Les Data Scientist doivent avoir une base solide en mathématiques et en statistiques. Ils doivent également comprendre et maîtriser la création de modèles d’apprentissage automatique et d’intelligence artificielle. Trouver un Data Scientist pour une entreprise est similaire à trouver un développeur Full-Stack et prend beaucoup de temps.
- Data Engineer : responsable de la collecte des données pertinentes. Ils déplacent et transforment ces données en un “Pipeline” pour l’équipe de Science des données. Ils peuvent utiliser des langages de programmation tels que Java, Scala, C++ ou Python, selon leur mission. Les ingénieurs de données se spécialisent dans les 3 actions principales des données : concevoir, construire et organiser les pipelines de données.
On peut les appeler les architectes des données. Les ingénieurs de données ont généralement des compétences techniques en informatique ou en science avec des compétences en développement de systèmes.
- Data Analyst : il participe également à la collecte de données pertinentes auprès de différentes sources et les prépare pour une analyse plus approfondie. Sur la base de cette analyse, un analyste de données doit tirer des conclusions et élaborer des rapports avec des illustrations.
Ainsi, nous pouvons voir que le travail des analystes de données est axé sur l’analyse et la description des stratégies passées ou basées sur les données passées ou actuelles, tandis que les Data Scientists se concentrent sur les prévisions et les calculs futurs pour élaborer des stratégies futures.
La charge de travail d’un Data Scientist
Lorsque vous regardez la branche de la Science des données, la plupart des gens diront que la Science des données = Apprentissage automatique. Cependant, en réalité, l’apprentissage automatique (ou la modélisation) ne représentera qu’environ 20% de la charge de travail d’un Data Scientist. La répartition des tâches pour un Data Scientist est la suivante :
- Comprendre les problèmes de l’entreprise : Relations et communications avec les dirigeants / les clients (15%)
- Travailler avec les données : Nettoyer les données, apprendre des données, visualiser, traiter, transformer, comprendre (70%)
- Transmettre les résultats : Rapports, préparation de diaporamas et création d’outils de prise de décision automatique (15%)
Les Data Scientists se basent sur l’analyse prédictive, l’apprentissage automatique, la gestion des données, les modèles mathématiques et les analyses statistiques. Un expert en données traitera de gros volumes de données selon le processus suivant :

Bien que le malentendu soit largement répandu, la construction de modèles d’apprentissage automatique n’est qu’une étape du processus de travail d’un Data Scientist. Une fois que les résultats du modèle sont en place, le Data Scientist les transmet aux gestionnaires, en utilisant souvent des moyens visuels. Une fois les résultats validés, le Data Scientist s’assure que le travail est automatisé et régulier.
Pour résumer, un Data Scientist doit :
- Appliquer des techniques quantitatives à partir de connaissances en statistique, économétrie, optimisation et apprentissage automatique / apprentissage en profondeur pour résoudre les problèmes commerciaux de divers domaines.
- Appliquer des méthodes statistiques pour construire des modèles prédictifs.
- “Ouvrir la voie” à la prise de décision basée sur les informations analytiques à partir de données structurées et non structurées.
- Identifier de nouvelles sources de données et explorer leur potentiel d’utilisation pour développer des informations supplémentaires dans le développement de produits.
- Découvrir les nouvelles technologies et les solutions d’analyse à utiliser dans le développement de modèles quantitatifs.
- Concevoir et développer des rapports et des tableaux de bord interactifs personnalisés.
- Maintenir et améliorer les modèles existants.
- Transmettre des idées et des analyses aux dirigeants et aux parties prenantes, ainsi qu’aux départements concernés pour la conduite du changement / de la mise à jour.
Parcours pour devenir Data Scientist en 2022

Bonne nouvelle pour tous ceux qui s’engagent dans le domaine de la Science des données : la courbe d’apprentissage de ce domaine n’est plus aussi abrupte qu’auparavant. L’entrée dans cette profession est maintenant beaucoup plus accessible, quel que soit votre parcours. Bien sûr, vous devrez faire preuve de persévérance en apprenant beaucoup, en comprenant beaucoup et en pratiquant beaucoup, mais vous pouvez avancer lentement et sûrement à partir des bases.
Les langages de programmation fondamentaux
Python
Python mérite une place importante et stable dans la boîte à outils d’un Data Scientist. De nombreux experts choisissent ce langage en raison de son écosystème spécialement conçu pour la science des données. Python dispose de la plus grande communauté d’analyse de données, ce qui facilite la recherche d’exemples d’analyse sur Kaggle, la recherche de problèmes sur Stackoverflow (un site de questions-réponses avec de bonnes questions pour les débutants et souvent des réponses de qualité) et les opportunités d’emploi, car c’est le langage le plus populaire sur le marché.
SQL
“Parler la même langue que les bases de données” est essentiel pour les Data Scientists. Vous devrez donc maîtriser le SQL (voir aussi Qu’est-ce que le SQL ?) pour pouvoir extraire des informations de la base de données en utilisant des requêtes sans avoir à écrire de code personnalisé.
R
Avec de nombreuses fonctionnalités spéciales, R est un langage “fait sur mesure” pour la science des données et est un bon point de départ pour les futurs Data Scientists. Toutes les informations et les problèmes de données seront traités avec R.
Hadoop
Bien que les connaissances de cet outil ne soient pas obligatoires, Hadoop ajoute de la valeur et une expertise spécialisée à un Data Scientist, en particulier s’il a une expérience de Hive ou Pig. Les outils cloud tels que Amazon S3 peuvent également être très utiles.
L’apprentissage automatique (Machine Learning)
Il n’y a pas d’échappatoire à l’apprentissage automatique (voir aussi Qu’est-ce que l’apprentissage automatique ?), vous devez donc absolument comprendre les bases du ML. Cela vous donnera une base de connaissances solide pour comprendre comment différents modèles fonctionnent à l’intérieur et même réfléchir à de meilleurs modèles pour chaque problème.
Il existe de nombreuses techniques populaires pour la plupart des modèles et vous devez apprendre ces techniques en premier, puis vous concentrer sur les différences mathématiques et les détails de leur mise en œuvre.
Les statistiques
La meilleure partie, la plus importante et malheureusement la plus difficile à la fin : les statistiques. Ce sont ces compétences qui distinguent un Data Scientist d’un Data Engineer. Il n’y a pas de raccourcis ici. Vous devriez commencer par les statistiques descriptives, savoir comment effectuer une analyse exploratoire de données décente (EDA) ou au moins avoir une connaissance de base des concepts de probabilité et d’inférence, comprendre les concepts de biais de sélection, le paradoxe de Simpson, les corrélations entre les variables (en particulier la méthode de la variance partitionnée), les bases de l’inférence statistique (et les célèbres tests AB comme exemple d’inférence courante sur le marché), et obtenir une idée de la conception de l’expérience.
Les compétences douces : pensée comme un Data Scientist
Améliorer et développer votre façon de penser en tant que Data Scientist est l’une des compétences clés pour distinguer un Scientist compétent d’un Scientist moyen. Voici quelques conseils pour vous améliorer :
- Soyez toujours curieux : Posez-vous des questions comme “Pourquoi ?” et cherchez de nouveaux liens et informations sur les problèmes de la vie quotidienne. Dans votre travail, les Data Scientists extraient des informations et des connaissances des données et des informations du jeu de données, puis prennent des décisions importantes en fonction de celles-ci. Une analyse parfaite ne sera pas utile si elle ne répond pas à un problème de base. Parfois, vous devez revenir en arrière, essayer une nouvelle approche et ajuster la question que vous essayez de résoudre. Posez toujours des questions.
- Soyez méticuleux : Les Data Scientists utilisent de nombreux outils pour gérer leur flux de travail, leurs données, leurs annotations et leur code. Il est important de travailler méticuleusement, d’observer, d’expérimenter et de prendre des notes en permanence, afin que vous puissiez revenir en arrière et réfléchir. De plus, vous devez enregistrer toutes les recherches et informations que vous avez découvertes, pas seulement celles d’aujourd’hui – mais aussi celles du passé.
- Soyez créatif : Cela peut sembler contradictoire, mais la Science des données doit être abordée de différentes manières – différents aspects et points de vue. Vous n’avez pas nécessairement besoin d’un background technique, mais vous devez avoir une pensée créative. En général, la pensée alternative est la clé pour résoudre un nouveau problème. C’est le complément de la pensée logique pour vous aider à réussir dans la recherche et l’analyse des insights.
- Ne vous inquiétez pas : Vous n’avez pas besoin d’être un expert en programmation, en finances ou d’avoir une expertise dans un domaine spécifique. De nombreux Data Scientists du monde entier viennent du droit, de l’économie ou de la science, ou même de la médecine. Tout est en vous et dans vos efforts. Si vous êtes flexible et travaillez de manière méthodique, vous pouvez vous familiariser avec les outils, les frameworks et les ensembles de données, ainsi que développer rapidement une compréhension de votre industrie et de ses problèmes.
Sources d’apprentissage pour les Data Scientists
Cours de Science des données populaires actuellement
- Machine Learning (Google ML) : Cours rapides en constante évolution de Google.
- Deep Learning (Kaggle Learn) : Nouveau produit de Kaggle à côté de la communauté Kaggle en plein essor, avec de petites explications théoriques et de nombreuses applications réelles.
- Python pour la Science des données et le Machine Learning (Udemy) : Explique de manière très claire les différents concepts de la Science des données et du Machine Learning. Ce cours vous aidera à maîtriser la bibliothèque de Machine Learning scikit-learn la plus utilisée. Il comprend également une introduction à Spark et à TensorFlow.
- Bootcamp SQL complet (Udemy) : Un Data Scientist a besoin de plus d’outils dans son arsenal que de simplement programmer en R et Python. SQL est un autre langage important que vous utiliserez souvent pour interagir avec des bases de données. Ce cours m’a aidé à obtenir mon stage actuel et m’a appris tout ce que je devais savoir sur SQL en deux jours seulement.
- DataCamp : Les cours de DataCamp durent de 4 à 6 heures. Ils comprennent de petites vidéos explicatives, suivies d’exercices pour appliquer les principes des vidéos. Tout se passe dans votre navigateur, vous n’avez donc rien à installer. Cela rend DataCamp parfait pour une introduction à la programmation en R et en Python.
Livres à lire pour les Data Scientists
- Machine Learning :
- Understanding Machine Learning: From Theory to Algorithms
- Deep Learning
- Machine Learning Yearning
- Statistiques :
- The Elements of Statistical Learning
- An Introduction to Statistical Learning with Applications in R
- Données :
- A Programmer’s Guide to Data Mining: The Ancient Art of the Numerati
- Mining of Massive Datasets
Github à suivre
Voici quelques références Github incontournables si vous vous lancez dans le domaine des DS :
- Awesome Deep Learning
- Awesome Machine Learning
- Awesome NLP
- Awesome RL
- Awesome Text Summarization
- Awesome Recommender Systems
J’espère que les informations fournies dans cet article vous ont donné une compréhension utile de ce qu’est un Data Scientist et des itinéraires de base pour devenir un Data Scientist. Le blog TopDev continuera à publier une série d’articles sur la Science des données dans un proche avenir. Ne manquez pas ça !
Vous pourriez également être intéressé par :
- La compilation de Cheat Sheets pour l’IA, les réseaux neuronaux, l’apprentissage automatique, l’apprentissage en profondeur et le Big Data
- La visualisation des données dans l’apprentissage automatique
- Le façonnage de la mentalité d’un Data Scientist
- Découvrir les opportunités d’emploi en tant que Data Scientist sur TopDev.