
Vous souhaitez implémenter un logiciel ETL pour intégrer des données éparses et hétérogènes, les préparer, les centraliser dans une base unique et mieux les exploiter ? Comme vous le savez surement déjà, il existe plusieurs familles de logiciels ETL, en simplifiant un peu, on peut distinguer les ETL Cloud vs on-premise, les ETL propriétaires vs open source. Nous avons réalisé un guide très complet pour vous aider à appréhender le marché en pleine ébullition des ETL.
Connaissez-vous vraiment la définition d’un outil ETL (ou d’un ELT) ?
Définition d’un ETL
L’acronyme « ETL » appartient à l’univers du Data Marketing. Avant de vous présenter les différents types d’ETL du marché, il n’est pas inutile de prendre le temps de définir clairement en quoi consiste un ETL. Par où commencer ? Partons des trois lettres qui composent cet acronyme :
- E, pour Extract (Extraire).
- T, pour Transform (Transformer).
- L, pour Load (Charger).
Cet acronyme, en un sens, dit déjà tout ! L’ETL est un process par lequel « on » extrait dans un premier temps les données, on les transforme et, enfin, on les charge. Cela ne nous fait pas beaucoup avancer. Ne vous inquiétez pas, vous allez y voir plus clair dans quelques lignes.
Au-delà, ETL désigne, par métonymie, les outils permettant de réaliser ce process. C’est pour cette raison que notre article est consacré aux outils ETL, aux outils qui permettent de mettre en place un process ETL. Voici une manière de représenter la place et le rôle d’un ETL dans une architecture IT. Le schéma est proposé par Informatica, l’un des leaders (voire LE leader) du marché des ETL on-promise :

Revenons sur les trois étapes de ce process :
Ingérer toutes les données… [Extract]
Aujourd’hui, les entreprises disposent de nombreuses sources de données. Les données qu’elles gèrent sont à la fois beaucoup plus nombreuses d’un point de vue volumétrique / quantitatif, et beaucoup plus diverses d’un point de vue qualitatif. Les entreprises ont potentiellement des dizaines de sources de données et bases de stockage différentes, elles récupèrent des données depuis leur site web, leur site e-commerce, leur ERP, leur système de caisse, leurs outils d’analytics, les réseaux sociaux, les outils de gestion des tickets clients type Zendesk, le CRM, le Marketing Automation, le logiciel d’emailing, les objets connectés, le mobile, etc. On pourrait poursuivre encore assez longtemps cette liste à la Prévert. Le développement des logiciels SaaS, si précieux qu’ils soient, à en partie contribué à multiplier les sources de données. L’augmentation du volume et de la diversité des données est à la fois une aubaine pour les entreprises et un défi. Les outils ETL ont pour vocation d’aider les entreprises à surmonter ce défi. Les données sont éparpillées dans un nombre important de silos. Les logiciels ETL sont des composantes d’une architecture IT visant à remédier au silotage des données. Nous y reviendrons.
Le travail premier d’un outil ETL est d’extraire toutes les données en provenance de la myriade d’outils et de bases utilisés par l’entreprise – via des connecteurs et des APIs. Pourquoi faire ? Pour les transformer ! (pourquoi faire ? on y vient rapidement…). Petite remarque : on pourrait dire « collecter » à la place d’ »extraire ». Malgré tout, « extraire » convient mieux, car les données que récupère l’outil ETL sont déjà dans l’entreprise, dans le SI de l’entreprise. Il ne s’agit pas de collecter des données nouvelles auprès des utilisateurs, des clients, mais d’extraire des données qui sont déjà dispersées dans le SI de l’entreprise et de les copier sur un serveur virtuel…pour en faire quelque chose : les transformer. Dernière remarque : il est possible de mettre en place des règles (sources à piper, vitesse de rafraîchissement, sources prioritaires…) pour définir les données à extraire. Un outil ETL n’extrait donc pas forcément TOUTES les données, même si il peut le faire.
Découvrez comment choisir le bon type de base de données pour son projet d’entreprise.
…Les transformer…[Transform]
Les entreprises ne parviennent plus à avoir une vision globale, unifiée, à 360° de leurs données clients. Trop de données, et surtout trop de sources de données, trop d’outils, trop de bases, trop de formats différents. L’objectif n’est pas de réduire le nombre d’outils qui compose la stack marketing. En tous cas ce n’est pas l’objectif des outils ETL. Les outils ETL, pour le dire très simplement, servent à mettre de l’ordre dans tout ce méli-mélo de données, à structurer les données non structurées, à restructurer des données déjà structurées mais pas comme il faut, à nettoyer les données, à les compiler, les agréger…bref, à transformer, sur un serveur intermédiaire, des données brutes en informations exploitables.
A ce stade, il faut bien comprendre la distinction entre structurer et transformer. Prenons l’exemple d’une enseigne de grande distribution qui dispose à la fois d’un site e-commerce et de points de vente physiques. L’outil d’ETL utilisé par l’entreprise va extraire, ingérer les données en provenance du site e-commerce et des points de vente physiques. Il s’agit bien plus que de structurer ces données – d’ailleurs, certaines le sont déjà. Toutes les données clients ne sont pas des données non-structurées, même si les données non-structurées constituent une part de plus en plus importante des données totales utilisées par l’entreprise. Au-delà du travail de structuration, les logiciels ETL transforment ces données pour que :
- Elles puissent être exploitées / analysées ensemble : pour que, par exemple, l’enseigne de grande distribution puisse analyser de manière agrégée le comportement de ses clients physiques et celui de ses clients e-commerce.
- Elles puissent être utilisées par la base de données marketing de l’entreprise. Les outils ETL « préparent » les données. Cette notion de préparation est la notion essentielle. On transforme pour préparer, et non l’inverse. Préparer les données consiste à leur donner un format adapté pour les cas d’usage que l’on souhaite implémenter dans la solution qui sert de base de données marketing. Les outils ETL rendent les données compatibles entre elles et avec le référentiel marketing cible. D’un point de vue technique (dans cet article, nous essayons d’être le moins technique possible…), cela consiste à agréger des tables de données entre elles pour créer une « super-table ». C’est comme si, en gros, vous aviez plusieurs tableaux Excel et que vous les agrégiez entre eux pour tout réunir sur un seul tableau et avoir ainsi une vue d’ensemble. C’est le travail que fait l’outil ETL. La forme que prend le « super tableau » et les données qu’il utilise dépendent des cas d’usage voulus par l’entreprise.
Il ressort de tout cela que les logiciels ETL sont des outils de traitement des données, et non pas seulement des gestionnaires de flux, des organisateurs de tuyaux. Ils ne se contentent pas de faire circuler la donnée dans le SI, ils la travaillent.
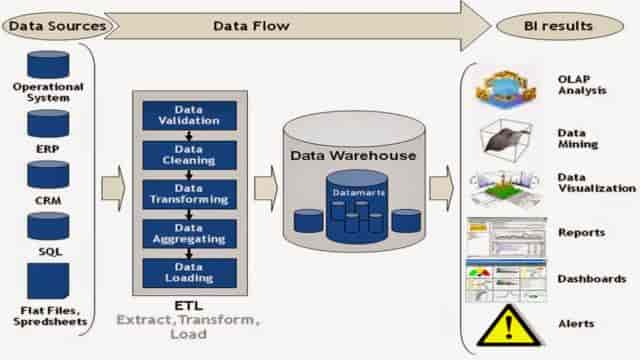
Le rôle de base de données marketing dont nous parlons depuis un instant est la plupart du temps joué par un Data Warehouse – ou entrepôt de données. Voici une autre schématisation d’un ETL, assez proche de la précédente à vrai dire. Elle est proposée par un blog dédié à la business intelligence :
…Les charger dans une base de données (un Data Warehouse par exemple) [Load]
Une fois sélectionnées, transformées, formatées, compilées, réconciliées, agrégées, préparées, les données sont envoyées / chargées dans un outil qui sert de base de données marketing. On l’a dit, en général, il s’agit d’un Data Warehouse. D’ailleurs, les deux vont nécessairement de pairs. Il n’est pas possible de monter un Data Warehouse sans utiliser un outil ETL. Car, dans un Data Warehouse, les données sont organisées…comme dans un entrepôt. C’est le contraire d’un Data Lake, qui est une sorte d’endroit fourre-tout qui ingère toutes les données sans aucune organisation. Un Data Warehouse stocke des bouteilles d’eau ; un Data Lake ressemble plutôt…à un plan d’eau justement. Grâce aux outils ETL, toutes les données stockées dans le Data Warehouse sont, en quelque sorte, disposées sur le même plan, sur le même niveau, en utilisant un langage commun. Il n’y a pas d’étages. Cela facilite la combinaison des données entre elles, l’exécution des requêtes, les travaux d’analyse et permet à l’entreprise de disposer de données de référence, d’une « single source of truth ». Un travail de Business Intelligence permet d’ajouter une couche d’intelligence dans le Data Warehouse et de créer des agrégats permettant de mieux exploiter les données stockées.
Découvrez notre comparaison entre les approches traditionnelle et Cloud pour une architecture Data Warehouse.
Profitons-en d’ailleurs, pour faire un petit aparté sur l’histoire des outils ETL. C’est dans les années 1970 que se sont développés les premiers logiciels ETL. Ils ne sont donc pas nés de la dernière pluie. A cette époque, les entreprises commençaient à utiliser plusieurs sources de données, à gérer différentes bases pour stocker différentes sortes de données business. Très tôt, le besoin s’est fait sentir d’agréger ces données (la problématique de l’éparpillement des données n’est donc pas nouvelle elle non plus…). C’est de là que sont nés les outils ETL : ils sont apparus pour processer toutes les données stockées par les entreprises, les transformer avant de les charger dans un outil cible. Au tournant des années 1980 – 1990, un type d’outil particulier s’est imposé comme solution de référence pour recevoir toutes ces données transformées et faire office de référentiel data : le Data Warehouse. Base de données d’un type particulier, le Data Warehouse permettait aux entreprises d’avoir accès aux données en provenance de tous les systèmes : les ordinateurs centraux, les micro-ordinateurs, les ordinateurs personnels, les feuilles de calcul, etc. En général, à cette époque, les entreprises utilisaient souvent plusieurs Data Warehouses et plusieurs ETL. Les organisations finissaient par se retrouver avec un ensemble d’outils ETL non intégrés entre eux. L’avantage, c’est que cela a contribué à l’augmentation du nombre d’éditeurs de logiciels ETL, à l’augmentation de la concurrence et donc à la diminution des prix. Hier réservés aux grandes entreprises, les outils ETL se sont largement démocratisés.
Pourquoi utiliser un outil ETL ?
Nous avons déjà largement répondu à cette question. Un outil ETL permet de mieux exploiter les données de l’entreprise dans un environnement SI complexe et composé d’une myriade de sources de données. Dit autrement, les outils ETL permettent d’améliorer l’accessibilité des données, de leur donner un sens (de transformer des données brutes en informations), de les rendre exploitable dans le cadre d’un stack marketing complexe.
Connecté à un Data Warehouse, les logiciels ETL aident les entreprises à acquérir une vision globale des données dont elles disposent. L’ETL est une méthode d’intégration des données qui a fait ses preuves. Ce n’est pas la seule, loin de là. Nous avons récemment publié un livre blanc très complet sur le sujet des Customer Data Platforms. Les CDP ingèrent toutes les données du SI, les traitent (segmentation, scoring, mise à jour en temps réel) et les redistribuent aux applications marketing & CRM. Elles remplacent l’architecture ETL + Data Warehouse. La petite différence, c’est qu’un outil ETL peut extraire, transformer et charger vraiment toutes les données de l’entreprise, et pas uniquement les données clients. Les CDP, comme leur nom l’indique, se concentrent sur les données clients. A noter que l’architecture CDP est plus cher qu’une architecture combinant ETL et Data Warehouse. Bref, revenons à notre sujet.
Lorsque l’on dispose d’un Data Warehouse, il est impossible de passer à côté d’un côté d’un outil ETL. L’outil ETL permet de structurer les données issues de toutes les sources et surtout de les préparer spécifiquement pour les usages qu’en fera le DWH. Coupler un outil ETL à un DWH permet de mener des analyser poussées sur les données de l’entreprise. Les outils ETL font aussi gagner beaucoup de temps aux équipes IT internes dans la mesure où, une fois les flux préparés, le Data Warehouse est alimenté en temps réel par l’outil ETL : le process ETL tourne de lui-même. Ce qui signifie beaucoup moins de scripts et de codes à gérer. Dernier avantage (qui nous vient à l’esprit en tous cas), les outils ETL permettent une plus grande souplesse dans la gestion de l’organisation de l’architecture SI : ils peuvent se connecter à n’importe quelle nouvelle source de données et gèrent parfaitement la scalabilité.
Découvrez notre comparaison des technologies envisageables pour votre Data Warehouse Cloud.
ETL VS ELT : Quelles différences ? Quelle solution choisir ?
Nous parlons depuis le début du process ETL…mais vous savez peut-être qu’il existe aussi le process ELT, pour Extract – Load – Transform : Extraire – Charger – Transformer. Quelle est la différence entre les deux ? Je suis sûr que vous avez déjà la réponse…dans le premier cas, on transforme avant de charger, dans le deuxième cas c’est l’inverse, on charge avant de transformer. Eh bien, c’est exactement ça ! Dans un process ELT, on extrait également les données à partir des sources de données de l’entreprise, mais on les charge dans la base sans les transformer. Les données sont transformées après avoir été chargées. Plusieurs remarques :
- Dans une architecture ELT, on n’utilise plus vraiment un Data Warehouse au sens précis du terme mais un Data Lake. On a donc deux options d’architecture :
- Data Warehouse + ETL
- Data Lake + ELT
- En utilisant un process ETL, les données qui arrivent dans la base ont déjà une couche d’intelligence. Elles sont exploitables, structurées. En utilisant un process ELT, les données qui arrivent dans le Data Lake n’ont aucune organisation, certaines n’ont aucune structure. Bref, c’est le bazar. Les données sont triées, structurées, normalisées après avoir été chargées.
- Les outils ETL travaillent les données, les structurent, les organisent, en retiennent certaines, en rejettent d’autres, en fonction des besoins de l’entreprise. Toutes les données n’entrent pas dans le DWH. En utilisant le process ELT, à l’inverse, toutes les données atterrissent pêle-même dans la base. Il n’y a aucun traitement, et donc beaucoup plus de données dans le Data Lake. L’entreprise a donc besoin de plus de ressources serveurs. Du point de vue de la Business Intelligence, cela permet de ne passer à côté de rien et de créer des agrégats plus pertinents. Les Data Lakes alimentés suivant un process ELT offrent plus d’opportunités d’exploration.
- Dans un process ELT, les flux de données sont beaucoup plus rapides : le temps entre le moment où les données sont extraites et celui où elles sont chargées dans la base est plus court. En contrepartie, les données qui arrivent dans la base nécessitent un travail plus long avant d’être exploitables.
Il ne vous aura pas échappé que cet article est dédié aux outils ETL…Cela ne signifie pas pour autant que l’option ETL soit toujours préférable à l’option ELT. Il y a des cas où cela fait tout à fait sens de privilégier un process ELT. Par exemple, si la vitesse de circulation des données dans le SI est quelque chose de très important pour le succès de votre entreprise, l’ELT peut être envisagé. Comme il n’y a pas de transformation des données, la donnée circule beaucoup plus vite. D’ailleurs, pour gagner du temps, le chargement et la transformation dans la base peuvent être réalisés en parallèle. Deuxième avantage du process ELT : lorsque l’on veut faire de la Data Science, du Machine Learning, identifier des schémas cachés, il est mieux d’utiliser un Data Lake pour ne passer à côté d’aucunes données. Par ailleurs, ce n’est pas parce que l’on juge une donnée inutile à l’instant t qu’elle le sera à l’instant t+1. Dans un Data Lake, on ne perd rien, l’entreprise a accès à toutes les données brutes historiques. Par contre, il est plus difficile de se conformer aux réglementations relatives à la protection des données personnelles (HIPAA, PCI, GPDR…) avec ce type d’architecture. De fait, mettre en conformité GPDR une architecture Data Lake / ELT est complexe…et coûteux. Aussi, la sécurité et la maintenance des données sont des sujets complexes dans l’ELT…Pour ces raisons, dans la plupart des cas, l’architecture ETL + Data Warehouse est plus pertinente.
Les différents types d’outils ETL
Un petit mot avant de commencer à vous présenter plusieurs solutions ETL. Il faut être conscient qu’il existe plusieurs types de logiciels ETL, plusieurs catégories. Au départ, ces différences peuvent ne pas être évidentes. On a tendance à penser que tous les ETL délivrent la même promesse. Ce qui, jusqu’à un certain point, est vrai, mais il faut aller plus loin dans l’analyse. Le point commun de tous les ETL, c’est qu’ils permettent d’extraire les données à partir de toutes les sources de données et de les charger sur des Data Warehouse divers et variés. Mais les éditeurs n’utilisent pas la même approche. Grosso modo, on peut répartir les outils ETL en deux grandes catégories :
- Il y a ceux, premièrement, qui sont orientés sur la synchronisation des données. Ce sont des synchronisateurs. Ils permettent de mettre en place des setups et des workflows permettant de faire circuler la donnée le plus rapidement possible, d’organiser les tuyaux qui relient les sources de données à la base de référence. Les interfaces utilisateurs de ce type d’outils tendent à mettre l’accent sur la visualisation du statut des synchronisations : elles visent la simplicité plus que la profondeur fonctionnelle. Leur principale principale préoccupation est moins de transformer la donnée que d’en optimiser au maximum la circulation entre les sources et la base cible. Des solutions comme Blendo, Fivetran, Segment et Stitch tendent à appartenir à cette catégorie.
- Deuxièmement, on pourrait regrouper certains ETL dans la catégorie des « transformateurs », par distinction avec celle des « synchronisateurs ». Ce sont des ETL plus évolués qui ne se contentent pas de synchroniser les données, mais permettent, en plus, de les transformer et de les enrichir. Ces outils ont, en général, un plus grand nombre d’applications et de fonctionnalités, leur structure de prix est plus complexe (basée sur le temps de calcul, le débit de données…), ils gèrent un plus grand nombre de sources de données, proposent des APIs, des log files…Cela va sans dire, ce sont des solutions souvent plus chères – aussi bien au niveau du coût d’acquisition que des coûts d’installation et de maintenance. Alooma, DataVirtuality, Etleap, Keboola, Xplenty appartiennent à cette catégorie.
Il est important d’avoir en tête ces distinctions avant de se lancer dans le choix d’un outil ETL. Si vous souhaitez surtout déplacer les données en provenance de vos sources third party dans des Data Warehouse centralisés, un outil ETL est probablement ce qui convient le mieux. A l’inverse, si vous travaillez surtout avec des log files et des fichiers de stockage génériques, un ETL « transformateur » vous aidera davantage à réaliser vos analyses.
Découvrez notre comparaison des modèles d’attribution – du Last Click au Data Driven.
Il existe d’autres axes de catégorisation des logiciels ETL, complémentaires de celui que l’on vient de présenter. Alooma, qui est un éditeur ETL, propose une catégorisation intéressante, qui met l’accent sur la distinction batch / temps réel. Elle est pertinente, même si elle n’est pas sans arrières-pensées de la part d’un éditeur qui propose une ETL en temps réel. Mais, de fait, le temps réel (ou le quasi temps réel) tend à se généraliser et à s’imposer comme la norme. Le schéma ci-dessus est intéressant pour comprendre l’évolution des outils :

Précisons le contenu de ces différentes catégories :
- La courbe « Legacy Batch » correspond aux ETL On premise historiques, héritiers directs des outils développés dans les années 1990. Ils ont dominé le marché jusqu’en 2010 en gros. A l’époque, les données étaient processées en batch, les batches pouvant durer des heures et des heures – entraînant des temps de mises à jour assez longs. Les outils On-Premise ont bien évolué depuis. Malgré tout, ils sont de moins en moins prisés aujourd’hui – car jugés (non sans raison) trop lourds, trop complexes à utiliser, mais aussi très coûteux.
- Les premiers ETL Cloud sont apparus en 2005. Avec ces outils, le serveur de l’ETL (là où les données transitent et sont transformées) est basé dans le Cloud, sur un serveur distant. L’apparition des ETL Cloud a permis de s’adapter à l’une des grosses évolutions des MarTech à l’époque : le développement du SaaS. Cette catégorie a connu une forte progression jusqu’en 2015. Depuis, la courbe stagne. A noter que, contrairement, à ce qu’indique le nom de la courbe, il y a eu dès le départ des ETL Cloud permettant de processer la donnée en temps réel.
- Troisième catégorie par son ordre d’apparition : les solutions ETL Open source. Eh oui, les ETL ont aussi leurs outils open source. La plupart ont été conçus au départ pour planifier des workflows, avec un processing en batch. Par exemple, Apache Airflow a été développé par les ingénieurs d’AirBnB et Apache NiFi par la NSA.
- La quatrième catégorie est transversale. Elle réunit tous les logiciels ETL qui ont pour point commun d’offrir un processing en temps réel.
Pour notre comparaison, nous avons choisi de retenir trois catégories d’outils ETL :
- Les ETL Cloud.
- Les ETL On-premise
- Les ETL Open source.
Les outils ETL Cloud
Commençons par les ETL Cloud. Ces solutions ont commencé à se développer au milieu des années 2000. Elles ont l’avantage d’être plus légères et moins coûteuses que les ETL traditionnels. Comme toutes les solutions SaaS, le modèle économique est celui de l’abonnement. Les ETL Cloud ont le vent en poupe, ils surfent sur une tendance très forte : le Cloud. De plus en plus de projets data sont montés sur le cloud, en associant un DWH Cloud et un ETL Cloud. Cette architecture offre en général plus de souplesse, une plus grande vitesse de processing (real-time), des intégrations plus simples à mettre en place…
StichData
Stitch Data, racheté par Talend pour près de 60 millions de dollars, est l’un des leaders sur le marché des ETL Cloud. Il peut être relié à un nombre assez varié de destinations : Amazon RedShift (le service de Data Warehouse d’Amazon), BigQuery, Snowflake…D’un autre côté, Stitch peut se brancher avec un nombre considérable d’applicatifs SaaS et de bases de données. L’un des grands avantages de Stitch, c’est que l’éditeur a développé un module Open Source (appelé Singer) qui permet aux utilisateurs de la communauté de développer de nouveaux connecteurs. Cela permet d’augmenter continuellement le nombre de connecteurs disponibles. Stitch met également une API et des web apps à destination de ses clients.
Côté prix, Stitch est l’une des solutions les plus abordables du marché. L’éditeur propose un plan gratuit jusqu’à 5 millions de lignes par mois et donne accès aux connecteurs gratuits. C’est l’un des rares éditeurs à proposer un plan gratuit. Comptez entre $100 et $1000 par mois pour les plans payants : de 5 à 250 millions de lignes par mois + accès aux intégrations premium.
A l’heure où ces lignes sont rédigées, nous venons d’apprendre que Stitch avait été racheté par Talend, un éditeur de logiciels français qui propose notamment l’une des solutions ETL open source de référence. Le rapprochement des deux éditeurs est très prometteur.
Découvrez 20 exemples de formulaires de haut niveau sélectionnés pour leur design et leur taux de conversion.
Fivetran
Fivetran est une solution plus robuste que Stitch. Elle s’intègre avec un plus grand nombre de sources et de bases cibles (Snowflake, Redshift, BigQuery, Azure). Fivetran permet d’aller un peu plus loin dans la transformation des données, de délivrer au Data Warehouse des données plus consistantes et cohérentes. Le support est également réputé pour être très réactif et très professionnel. Les prix de Fivetran ne sont pas publics. Ils sont proposés sur-mesure. Une chose est sure, il n’y a pas de plan gratuit mais en revanche une période d’essai gratuit de 14 jours.

Xplenty
Xplenty est un autre intégrateur de données réputé, aux possibilités d’intégration très grandes. Quelques chiffres : à l’heure où ces lignes sont écrites, SnowXplenty propose des connecteurs avec 20 bases de données (Snowflake, Microsoft Azure, Oracle, PostgreSQL, MS SQL, Google BigQuery…), 5 bases de données Cloud (Amazon S3, Google Cloud Storage, HDFS…), plus de 100 applicatifs cloud, une dizaine d’outil d’analytics, une dizaine d’outils publicitaires (Facebook Ads, Bing Ads, AdWords…), 3 BI, etc. Le support client, comme celui de Fivetran, est très réputé. Les abonnements sont sur-mesure, mais Xplenty a la réputation d’être un éditeur assez abordable.
Découvrez pourquoi les Customer Data Platforms vont s’imposer dans les prochaines années.
Alooma
Dernier outil ETL Cloud de notre sélectipon : Alooma, un ETL qui peut être connecté à à peu près toutes les sources de données et à peu près tous les services de Data Warehouses. Bon, c’est un peu exagéré, mais malgré tout Alooma, lancé en 2013, est un excellent outil ETL. Vous pouvez charger les données dans une dizaine de bases cibles : S3, Redshift, BigQuery, Snowflake, MySQL, Periscope Data, PostgreSQL, Azure…Nous n’avons pas compté le nombre de bases de données et d’applicatifs que vous pouvez connecter à Alooma, mais c’est considérable. Les tarifs sont sur-mesure.
Nous voudrions, avant de passer à l’autre catégorie d’outils ETL, insister sur un point qui nous semble important. La plupart des éditeurs de ces ETL SaaS sont des startups très innovantes, pleines d’imagination et de talents. Les solutions proposées sont de grande qualité, très souples, évolutives, en perpétuel enrichissement (de features, d’intégrations…). Ce sont des solutions qui tiennent clairement la route. Mais il y a une vraie différence – quasiment de nature – entre ces outils ETL Cloud et les ETL traditionnels comme Informatica (que nous allons présenter dans un instant). A l’occasion d’une discussion très intéressante sur Reddit, le CEO de Fivetran l’a d’ailleurs parfaitement reconnu : « Il y a quelques malentendus quand on cherche à comparer une entreprise comme la nôtre (ndlr Fivetran) ou Allooma et une plateforme ETL comme Infomatica. Fivetran est vraiment un outil de réplication, pas un outil ETL à proprement parler – vous utilisez Fivetran parce que vous avez des connecteurs pré-construits aux sources de données dont vous avez besoin – nous, Fivetran, on s’occupe de tout répliquer dans votre Data Warehouse sans aucune intervention de votre part. Ensuite, c’est à vous de faire vos transformations personnalisées en utilisant des requêtes SQL. C’est une répartition du travail gage de productivité ».
En clair, et c’est un point que nous avions déjà abordé plus haut, les logiciels ETL Cloud sont essentiellement des « synchronisateurs ». Leur rôle est de synchroniser les données en provenance de toutes vos sources dans votre base cible (DWH Cloud). Ils n’interviennent pas tellement dans la transformation des données – leurs fonctionnalités, sur ce terrain, sont en vérité assez limitées. En résumé, on devrait plutôt parler d’outils « EL Cloud » – même si, encore une fois, il ne faut sous-estimé le potentiel d’évolution de ces solutions.
Les solutions ETL « on premise »
Pour ceux qui ne sont pas familiers du terme (on sait jamais), les logiciels « on-premise » désignent tous les logiciels « à installer ». Ils sont installés directement sur les serveurs de l’entreprise par opposition aux logiciels Cloud / SaaS qui sont installés sur des serveurs distants gérés par les éditeurs. La différence porte sur la localisation des serveurs (qui a beaucoup d’incidence sur les questions de contrôle, d’accès, de sécurité, de maintenance…) mais aussi sur le modèle économique. Les logiciels on premise utilisent le modèle de la licence, renouvelée tous les ans, contrairrement aux logiciels SaaS qui utilisent le modèle de l’abonnement (mensualisé ou annualisé).
Les solutions on-premise sont les représentants historiques du marché des ETL. Ce sont, comme on l’a vu, les solutions les plus lourdes, les plus complexes à utiliser et les plus chères. Pour le coût de la licence, comptez au minimum 50k – 100k par an. A ce coût doivent s’ajouter les coûts élevés d’installation et de formation (il y a une grosse courbe d’apprentissage). Le marché des ETL on-premise comporte de très nombreux acteurs. Gartner a conçu un quadrant qui permet de visualiser les différents acteurs et leur répartition d’après deux axes : la simplicité/complexité d’utilisation ; la richesse fonctionnelle. Nous le reproduisons :

Nous avons souhaité vous présenter 4 solutions : Informatica PowerCenter, SAS, IBM InfoSphere DataStage et Microsoft SSIS.
Informatica PowerCenter
Informatica PowerCenter reste LE leader du marché des ETL on premise. L’outil dispose d’une très grande profondeur fonctionnelle, est entièrement scalable, affiche des performances de premier de la classe. Il peut être utilisé pour tous les projets liés à de l’intégration de données : gouvernance des données, migration de données, entreposage de données, replication et synchronisation de données, Master Data Management (MDM), etc. Informatica cible les grandes organisations et s’adresse aux entreprises souhaitant développer de gros projets data. Informatica permet vraiment de compiler toutes les données de l’entreprise. Il gère toutes les sources. PowerCenter gère aussi bien le batch que le temps réel, propose un gestionnaire de meta-données, des outils de Data Visualization. Informatica est constitué de trois principaux composants : une interface client qui permet de gérer les meta-données, le répertoire, de définir les règles métiers, etc. ; un répertoire qui stocke toutes les données ; un serveur connecté aux sources et aux bases cibles où sont transformées et chargées les données. Informatica est un mastodonte. C’est sans doute la solution la plus onéreuse du marché…
SAS
IBM InfoSphere DataStage

IBM InfoSphere DataStage est un produit IBM proposant à la fois un service de Data Warehousing et un service ETL. C’est d’ailleurs un point que l’on peut souligner. En général, les gros acteurs de DWH finissent tous par développer leur propre ETL. Les fonctionnalités d’InfoSphere Data Stage se répartissent en 4 catégories :
- Le profiling des sources de données, qui consiste à comprendre et modéliser les sources de données dans le but de détecter des incohérences, des anomalies et des problèmes au niveau des données. IBM permet de faire du Machine Learning.
- La gestion de la Data Quality : nettoyage, formatage, standardisation, actualisation, fusion des données…
- La Data Transformation : IBM offre d’étonnantes possibilités en matière de transformation des données.
- La transmission des données aux utilisateurs finaux.
IBM InfoSphere DataStage a fait évoluer son modèle tarifaire pour le rapprocher des modèles d’abonnement pratiqués par les ETL Cloud. Cela permet davantage de progressivité dans les coûts et des tarifs globalement inférieurs à ceux des autres ETL on premise.
Microsoft SSIS
Le SQL Server Integration Services (SSIS) est l’outil ETL développé par Microsoft. Il s’agit d’un outil très complet qui permet de gérer les synchronisations, les migrations de données, leur transformation et leur intégration dans le Data Warehouse. SSIS peut extraire des données de différentes sources et de différents formats : bases de données relationnelles / transactionnelles, fichiers csv, xml, txt, FTP, applications, etc. Il est possible de créer des connecteurs sur-mesure. Les possibilités en termes de transformation sont vraiment très grandes. SQL Server Integration Services est apparu en 2005 comme une composante de Microsoft SQL Server. Il a remplacé le précédent ETL de Microsoft : Data Transformation Services (DTS). L’un des avantages de SSIS, c’est qu’il est très simple et rapide à implémenter et à intégrer avec les services Azure. La documentation est d’ailleurs accessible en français.
Les outils ETL open source
Passons, pour finir, à la dernière catégorie : les logiciels ETL open source. Ils constituent une alternative intéressante aux solutions propriétaires – une alternative gratuite (attention toutefois à ne pas oublier les coûts de déploiement…). Leur développement est associé à celui des solutions de Business Intelligence open source (OSBI) : Pentaho, SpagoBI, JasperIntelligence…
L’utilisation de ces solutions est en revanche plus complexe que les outils ETL Cloud et la connectivité est souvent moins développée, même si, open source oblige, libre à vous de développer des connecteurs spécifiques…Nous avons sélectionné 4 outils : Apache AirFlow, Apache Kafka, Cloudera et Talend ETL
Apache AirFlow
Construit sous Python, Apache Airflow est un outil d’automatisation de workflows et de planification qui peut être utilisé pour concevoir et gérer des pipelines de données. Airflow n’est pas à proprement parler une plateforme de gestion des flux de données. Les « tâches » représentent des mouvements de données, mais elles ne déplacent pas les données en tant que telles. Ce n’est pas un outil ETL « interactif ». Il existe un grand nombre de plugins permettant d’ajouter des fonctionnalités, de renforcer la connectivité avec des plateformes de stockage (de type Amazon RedShift, MySQL…) et de manipuler de manière plus complexe les données et meta-données. Apache Airflow propose par ailleurs des connecteurs avec Amazon Web Services (AWS) et Google Cloud Platform (GCP) (qui inclut BigQuery).
Apache Kafka

Apache Kafka a été développé en 2012 au sein de l’incubateur Apache, comme Apache Airflow. Au départ, il s’agit d’une plateforme de streaming distribuée open source. Mais, avec le temps, les cas d’usage se sont considérablement élargis. Aujourd’hui, Kafka est une plateforme permettant de centraliser le stockage et l’échange en temps réel de l’ensemble des données de l’entreprise. Kafka est beaucoup utilisé pour mettre en place des process ETL en temps réel. Pour l’extraction et le chargement, on utilise la brique Kafka Connect ; pour la transformation, on utilise Kafka Streams.
Cloudera Data Hub (CDH)
Cloudera est l’un des premiers pure-players à s’être emparés d’Hadoop, un framework libre et open source écrit en Java. L’éditeur a développé plusieurs solutions commerciales mais soutient aussi un certain nombre de projets open source Hadoop, donc CDH. CDH est l’une des distributions Hadoop les plus complètes, testées et populaires. Cloudera permet d’utiliser le framework Hadoop au meilleur de ses capacités. L’un des cas d’usage de Cloudera Data Hub est la construction de process ETL.
Talend ETL
Talend est un éditeur de logiciels français qui développe des solutions propriétaires et des produits open source, parmi lesquels Open Studio, un logiciel d’intégration des données qui est aussi le produit historique de la marque. OpenStudio permet de disposer d’un outil ETL relativement simple à implémenter et très complet. Il propose notamment une belle variété de connecteurs avec des système de gestion de bases de données (Oracle, Teradata, Microsoft SQL Server…), des logiciels SaaS CRM & Marketing (Marketo, Salesforce…), des suites (SAP, Microsoft Dynamics, Sugar CRM)…
Voilà, nous espérons vous avoir éclairé sur le fonctionnement de l’ETL et la répartition des principaux acteurs. Si vous avez des questions concernant ce sujet complexe ou votre problématique IT, n’hésitez pas à nous contacter.