
Introduction
Salut tout le monde,
Aujourd’hui, dans le cadre de notre série sur l’analyse des données commerciales, je vais partager avec vous les concepts les plus courants liés à la conception des systèmes de données. En effet, lorsque nous effectuons des analyses de données, il est important de comprendre ces concepts. Je ne suis pas spécialiste des connexions de bases de données, je suis principalement axé sur l’analyse. Cependant, nous avons un expert en gestion et en architecture de bases de données dans notre équipe (Joseph Tan) et nous finalisons actuellement le programme de formation “Enterprise Data Warehouse”. J’espère que nous lancerons bientôt ce nouveau programme.
Les différents référentiels de données
Les différents termes tels que “bases de données”, “data warehouses”, “data lakes”, “data marts” et “data lakehouses” peuvent être regroupés sous le terme général de “référentiels de données” (source). Malheureusement, je ne connais pas l’équivalent exact de ce terme en français.
Base de données
Une base de données est un endroit où les données pertinentes sont stockées pour répondre à une situation spécifique. Par exemple, une base de données de points de vente (POS) collecte et stocke toutes les données relatives aux transactions d’un magasin de détail.
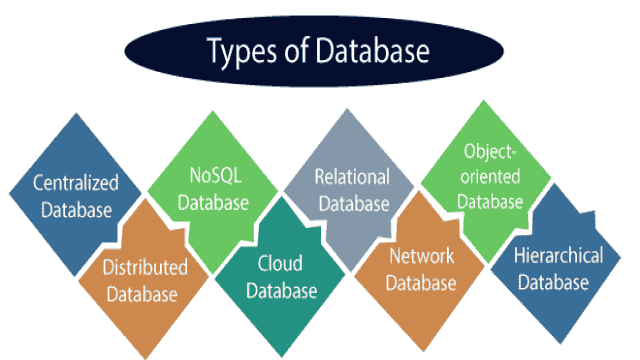
Il existe différents types de bases de données : [image de types de bases de données]
Les nouvelles données sont traitées, organisées, gérées, mises à jour et finalement stockées dans des tables. Une base de données est un entrepôt de données destiné uniquement aux données brutes de transaction. Étant donné que la base de données est étroitement liée aux transactions, elle effectue le traitement des transactions en ligne (OLTP – Online Transactional Processing).
En regardant l’image ci-dessus, après les bases de données, les données sont transférées vers des outils d’extraction, de transformation et de chargement (ETL) pour les transférer vers le data warehouse. Un data warehouse stocke généralement des données structurées (structured data).
Comparaison entre base de données et data warehouse
Alors que le data warehouse est un référentiel de données polyvalent pour différents cas d’utilisation, le data mart est une partie supplémentaire du data warehouse, conçue et construite spécifiquement pour un département/fonction commerciale spécifique.
Voici quelques avantages de l’utilisation d’un data mart:
Séparation sécurisée des données: Étant donné que le data mart ne contient que des données spécifiques à ce département, vous êtes assuré que les données ne seront pas accessibles indûment (données financières, données de revenus, etc.).
Performance séparée: De même, étant donné que chaque data mart est utilisé pour un département spécifique, les performances de chaque data mart peuvent être gérées et optimisées indépendamment, sans affecter les autres tâches d’analyse. Il existe trois types de data marts :
- Data Mart dépendant – Créé à partir du data warehouse existant, il adopte une approche descendante en stockant toutes les données commerciales de votre organisation en un seul emplacement centralisé. Ensuite, une partie spécifique des données est extraite pour l’analyse lorsqu’elle est nécessaire.
- Data Mart indépendant – Un data mart indépendant est un système autonome créé sans utiliser de data warehouse et se concentre sur une fonction métier spécifique. Les données sont extraites de sources de données internes ou externes, affinées, puis chargées dans le data mart où elles sont stockées jusqu’à ce qu’elles soient nécessaires ou analysées.
- Data Mart hybride – Un data mart hybride intègre les données à la fois du data warehouse actuel et des systèmes sources supplémentaires. Il combine la vitesse et la focalisation sur l’utilisateur final d’une approche descendante avec le support de l’intégration d’entreprise d’une approche ascendante.
Choisir un Data Lake pour deux raisons principales
Vous avez besoin d’un moyen économique de stocker différents types de données en grande quantité. Vous n’avez pas encore de plan précis pour ces données, mais vous prévoyez de les utiliser à un moment donné. Par conséquent, vous collectez les données d’abord et les analysez plus tard.
Comparaison entre Data Warehouse et Data Lake 
Comparaison entre Data Lake, Data Warehouse et Data Mart 
En regardant les images ci-dessus :
Le Data Lake convient aux entreprises qui ont besoin d’effectuer des analyses avancées (utilisant à la fois des données structurées et non structurées). Les requêtes et l’analyse des données prennent du temps (hebdomadaire/mensuel), les coûts sont élevés en raison de la grande quantité de données à stocker, et seuls quelques groupes d’utilisateurs sont capables d’utiliser des analyses avancées.
Le Data Warehouse est le référentiel de données global qui rassemble des systèmes de données structurées de différents départements. Il est très courant dans la plupart des entreprises, où il y a déjà de multiples systèmes de données dans différents départements, et où ces systèmes sont maintenant consolidés en un seul endroit. La plupart des utilisateurs métiers peuvent accéder à ces données. Il s’agit du référentiel de données global de l’entreprise.
Le Data Mart est un référentiel de données séparé, conçu spécifiquement pour chaque département.
Data Lakehouse
Un Data Lakehouse combine les avantages d’un Data Lake et d’un Data Warehouse.
Data Fabric est conçu pour aider les organisations à résoudre des problèmes de données complexes. Il permet de gérer leurs données quelle que soit l’application, la plate-forme ou l’emplacement de stockage des données. Il permet un accès transparent et le partage de données dans un environnement de données distribué. Il est similaire au Data Lakehouse, qui combine Data Warehouse et Data Lake, mais il va plus loin en intégrant également des données d’applications entre elles. Les Data Fabrics vont plus loin en fournissant des services de contrôle, de surveillance, etc. pour vous et votre entreprise.
Bien que le Data Mesh tente de résoudre des problèmes similaires à ceux de la Data Fabric (c’est-à-dire la gestion des données dans un environnement de données hétérogène), il résout le problème de manière fondamentalement différente. En résumé, alors que la Data Fabric vise à construire une seule couche de gestion virtuelle sur les données distribuées, le Data Mesh permet à des équipes distribuées de gérer les données quand elles le jugent nécessaire, bien qu’avec quelques directives de gouvernance communes.
Next Data Platform est le Data Mesh ?
Le Data Mesh est une “nouvelle étoile montante” lorsqu’on parle de types de stockage de données actuels. Avant de comprendre ce qu’est le Data Mesh, examinons ensemble deux concepts importants : Architecture monolithique vs architecture microservices.
Architecture monolithique :
Dans l’ingénierie logicielle, l’architecture monolithique est considérée comme un modèle traditionnel dans lequel une application est construite comme un bloc unique, fermé et indépendant des autres applications.
Cette approche est pratique pour les premières phases du cycle de vie de tout projet, car elle facilite le développement et le déploiement du code. En d’autres termes, l’approche monolithique permet la mise en œuvre simultanée de toutes les fonctionnalités et, comme tout dans la vie, elle a ses avantages, notamment :
- Une vitesse de développement plus lente
- L’adoption de nouvelles technologies
- La scalabilité du développement et du déploiement
Architecture microservices :
D’autre part, la méthode des microservices est une approche architecturale basée sur une série de services pouvant être déployés indépendamment. Ces services ont leur propre base de données et leur propre logique métier avec un objectif spécifique. Les mises à jour, les tests, les déploiements et les évolutions se font sur chaque service. Cela permet de contourner les inconvénients de l’approche monolithique, mais crée également de nouveaux problèmes. Par exemple :
- Complexité accrue du développement
- Coûts d’infrastructure élevés
- Difficultés de débogage
- Manque de propriété claire
Qu’est-ce que le Data Mesh ?
Le Data Mesh est le pendant de l’architecture microservices pour les plates-formes de données. Selon Zhamak Dehghani, consultante chez ThoughtWorks, qui a proposé cette définition pour la première fois : “Le Data Mesh est une architecture de plate-forme de données qui embrasse l’omniprésence des données dans l’entreprise en tirant parti d’une conception orientée domaine auto-entretenue, en se basant sur la théorie de la conception dirigée par le domaine de Eric Evans, un modèle de développement logiciel flexible qui peut s’adapter à la structure et au langage de votre entreprise avec son propre domaine métier respectif”.
En d’autres termes, contrairement à l’infrastructure de données centrale qui gère l’entrée, le stockage, la transformation et la sortie des données dans un data lake central, le Data Mesh prend en charge les consommateurs de données distribuées, orientées domaine et avec une approche “data-as-a-product”, où chaque domaine gère ses propres pipelines de données. La liaison de ces domaines et de leurs actifs de données connexes est une couche de capacité d’interaction commune appliquant une syntaxe et des normes de données communes.
De nombreuses entreprises ont jusqu’à présent tiré parti d’un entrepôt de données unique connecté à de multiples plateformes de business intelligence. De telles solutions entraînent souvent une dette technique importante dans la maintenance des pipelines par une petite équipe d’ingénieurs de données, ce qui entraîne des goulots d’étranglement dans la plate-forme de données de l’organisation.
Plutôt que cela, les architectures de données orientées domaine, comme les data meshes, offrent aux équipes le meilleur des deux mondes : une base de données centralisée (ou un data lake distribué) avec des domaines (ou des domaines d’activité) responsables de la gestion de leurs propres pipelines. Comme le soutient Zhamak, les architectures de données peuvent être le plus facilement mises à l’échelle en les décomposant en composants plus petits et orientés domaine.
En d’autres termes, plus les besoins en infrastructure de données de votre entreprise sont complexes et exigeants, plus votre organisation est susceptible de bénéficier d’un data mesh.
Voici un exemple de Data mesh à un niveau “élevé” : (images de l’architecture du data mesh)
En conclusion, j’ai utilisé les définitions académiques de ces concepts, vous pouvez consulter les liens pour des informations plus détaillées. J’ai regroupé ces informations pour ceux d’entre vous qui souhaitent en savoir plus :
- Différence entre data mart, data warehouse, base de données et data lake
- Différence entre data lake, data warehouse et data mart
- Data Mesh
- Les types de bases de données
- Microservices vs architecture monolithique
- Data Mesh en pratique
- Data Mesh sur une plate-forme de mode en ligne
Merci d’avoir pris le temps de lire cet article. À bientôt pour les prochains articles ! Consultez notre site https://indaacademy.vn/ pour voir notre offre de cours en ligne et en présentiel pour les compétences en analyse de données commerciales.
L’INDA Academy est le leader de la formation en analyse de données commerciales au Vietnam. Nos cours sur l’analyse de données commerciales sont dispensés régulièrement, avec plus de 100 participants par classe. Nous sommes le seul centre de formation en analyse de données commerciales au Vietnam à attirer un grand nombre d’étudiants par classe. Nous avons déjà organisé 34 cours publics sur le marché et nous sommes partenaires de formation en analyse de données pour de grandes entreprises au Vietnam.