
Apache Druid est une véritable révolution dans le domaine de l’analyse en temps réel. Son architecture conçue spécifiquement permet une ingestion, un stockage et une récupération rapides des données pour les requêtes analytiques. Druid est l’un des seuls produits dans le domaine des bases de données analytiques qui propose une découverte automatique du schéma. Cela offre une capacité inégalée à s’adapter à des sources de données diverses et en constante évolution, éliminant ainsi la nécessité d’une définition et d’une maintenance manuelles fastidieuses du schéma. Cette fonctionnalité permet aux utilisateurs de se concentrer sur l’analyse et les insights des données plutôt que de passer du temps et des efforts à gérer et mettre à jour les schémas.
Dans cet article de blog, nous allons configurer une ingestion sans schéma qui permet de détecter automatiquement les modifications des données. Nous allons également créer des messages, les publier sur Kafka et les ingérer dans Druid. Nous couvrirons tout, de la configuration de votre environnement Druid à l’ingestion de messages en continu depuis Kafka pour traiter des données en temps réel.
Découverte automatique du schéma dans Druid
La détection automatique du schéma est particulièrement utile pour les bases de données analytiques pour plusieurs raisons, notamment les suivantes :
Flexibilité : Les bases de données analytiques traitent souvent des sources de données diverses et en évolution. Grâce à la détection automatique du schéma, la base de données peut s’adapter automatiquement à différentes structures de données et gérer les modifications de schéma sans intervention manuelle d’un administrateur de base de données. Cela est particulièrement utile pour les données en streaming qui changent fréquemment et sont événementielles. Cette flexibilité supplémentaire permet une exploration et une analyse efficaces et agiles des données.
Gain de temps : La définition et la maintenance manuelles des schémas pour chaque source de données peuvent être une tâche chronophage et sujette aux erreurs. La détection automatique du schéma automatise cette tâche, ce qui permet de gagner du temps et des efforts pour les administrateurs de bases de données et les ingénieurs de données.
Scalabilité : Les bases de données analytiques traitent généralement de grandes quantités de données. La détection automatique du schéma permet à la base de données de gérer des tailles et des structures de données variables de manière transparente. Lorsque de nouvelles sources de données sont ajoutées ou que des sources existantes évoluent, la base de données peut ajuster dynamiquement ses capacités de détection du schéma, garantissant ainsi une scalabilité sans compromettre les performances.
Facilité d’utilisation : La détection automatique du schéma simplifie le processus d’intégration des nouvelles sources de données. Au lieu d’exiger des utilisateurs de définir le schéma au préalable, la base de données peut déduire automatiquement la structure et rendre les données disponibles pour l’analyse. Cela améliore l’utilisabilité de la base de données analytique et réduit les obstacles à l’entrée pour les utilisateurs.
Assurance qualité des données : La détection automatique du schéma peut également aider à identifier les problèmes potentiels de qualité des données. En analysant la structure et les motifs des données, la base de données peut signaler les incohérences ou les anomalies qui nécessitent une enquête ou un nettoyage supplémentaires. Cela garantit l’exactitude des données et améliore la fiabilité des insights analytiques.
Dans l’ensemble, la détection automatique du schéma dans une base de données analytique simplifie le processus d’ingestion des données, prend en charge des sources de données diverses, améliore les capacités d’exploration des données et prend en charge la scalabilité pour traiter de grandes quantités de données.
Prérequis
Pour commencer, vous devrez installer et configurer Apache Druid sur votre machine locale ou votre serveur. Ensuite, installez Kafka localement, écrivez un producteur Kafka pour envoyer des messages et configurez la configuration d’ingestion dans Druid pour activer la détection automatique du schéma.
Installer Druid localement
- Téléchargez la dernière version de Druid depuis apache.org et extrayez le fichier.
- À partir du terminal, accédez au répertoire de distribution, par exemple :
cd druid_26/distribution/target/apache-druid-27.0.0-SNAPSHOT
- À partir de la racine du package apache-druid-26.0.0, exécutez la commande suivante pour démarrer la configuration micro-quickstart :
./bin/start-druid
- Cela lance les instances de ZooKeeper et des services Druid.
- Après le démarrage des services Druid, ouvrez l’interface utilisateur Web à l’adresse http://localhost:8888.
Remarque : Pour arrêter Druid à tout moment, utilisez CTRL+C dans le terminal. Cela arrête le script de démarrage et met fin à tous les processus Druid.
Installer Kafka
Apache Kafka est un bus de messages à haut débit qui fonctionne bien avec Druid.
- Téléchargez la dernière version de Kafka à l’aide de commandes similaires à celles ci-dessous (en fonction de la version de Kafka) dans votre terminal :
curl -O https://archive.apache.org/dist/kafka/2.7.0/kafka_2.13-2.7.0.tgz
- Décompressez le fichier .tgz :
tar -xzf kafka_2.13-2.7.0.tgz
- Accédez au répertoire Kafka en cours d’utilisation :
cd à l'emplacement du dossier kafka_2.13-2.7.0
- Dans le répertoire racine de Kafka, exécutez cette commande pour démarrer un courtier Kafka :
./bin/kafka-server-start.sh config/server.properties
Remarque : Pour arrêter Kafka à tout moment, utilisez CTRL+C dans le terminal. Cela arrête le script de démarrage et met fin à tous les processus Kafka.
Créer un sujet Kafka
Exécutez la commande ci-dessous depuis une fenêtre de terminal pour créer un sujet appelé test_topic.
./bin/kafka-topics.sh -create -topic test_topic -bootstrap-server localhost:9092
Créer un producteur Kafka
Définissez un producteur Kafka pour créer et envoyer des messages à Kafka (voir l’exemple de code ci-dessous).
from kafka import KafkaProducer
import json
import time
def simple_message():
return {
"message": "This is a sample message",
"timestamp": int(time.time()),
"id": str(uuid.uuid4())
}
def send_simple_messages(producer, topic, num_messages):
for _ in range(num_messages):
message = json.dumps(simple_message())
producer.send(topic, value=bytes(message, 'utf-8'))
producer.flush()
def run_producer(bootstrap_servers, topic, num_messages):
producer = KafkaProducer(bootstrap_servers=bootstrap_servers)
send_simple_messages(producer, topic, num_messages)
producer.close()
bootstrap_servers = 'localhost:9092'
topic = 'test_topic'
num_messages = 10
run_producer(bootstrap_servers, topic, num_messages)Le code ci-dessus initialise un producteur Kafka pour envoyer des messages vers un sujet Kafka spécifié. La fonction run_producer configure le producteur Kafka avec le serveur d’amorçage configuré sur localhost:9092 et le sujet défini sur test_topic, en utilisant une boucle pour générer le nombre de messages spécifié.
La fonction send_simple_messages construit et envoie des messages individuels. Chaque message est généré par la fonction simple_message, qui crée un dictionnaire contenant un message personnalisé avec l’horodatage actuel et un identifiant unique. Ce dictionnaire est ensuite converti en une chaîne au format JSON qui est envoyée vers le sujet Kafka via le producteur. Après l’envoi de chaque message, le producteur est vidé avant la fin du script.
Création d’une source de données en continu
Le traitement des données en temps réel est essentiel pour de nombreuses applications aujourd’hui, ce qui fait d’Apache Druid un outil indispensable pour l’ingestion et l’analyse transparentes des données en continu grâce à son intégration transparente avec Kafka.
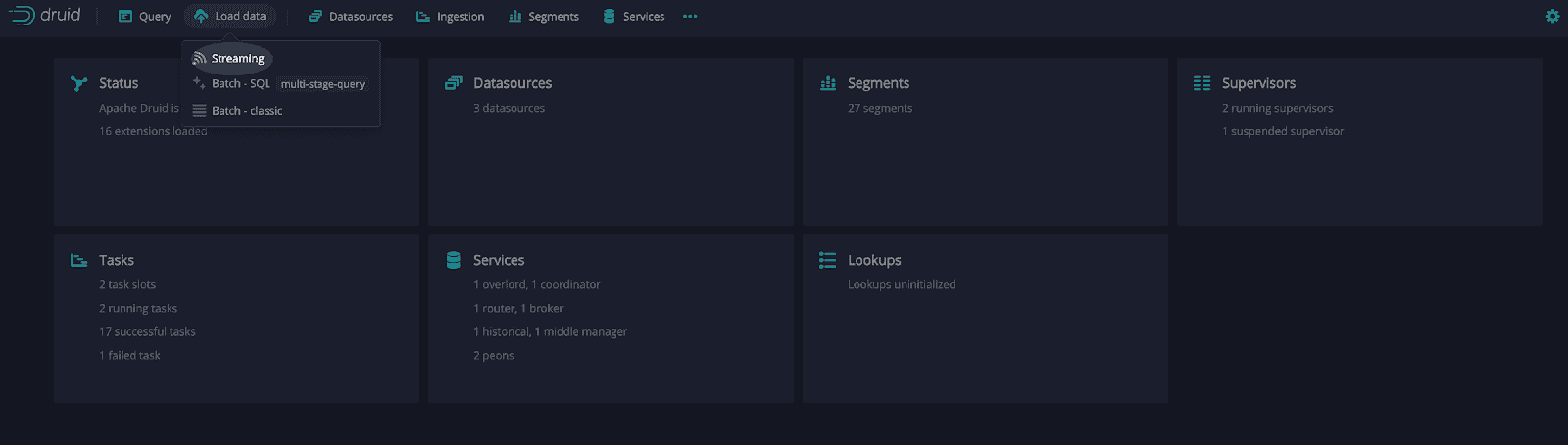
Créons une tâche pour charger des données depuis l’interface utilisateur de Druid. À partir de la page d’accueil, sélectionnez “Charger des données” puis “En continu”.

Ensuite, sélectionnez “Apache Kafka” et “Connecter des données”.

Ajoutez le serveur d’amorçage pour le courtier Kafka. Comme nous exécutons Kafka localement, le serveur est localhost:9092.
Ajoutez le nom du sujet que nous avons créé précédemment, test_topic.
Sélectionnez “Appliquer”.

Assurez-vous que Kafka est démarré et exécutez le code précédent pour générer et envoyer des messages. Les messages seront affichés dans l’interface “connect”.
Examinez quelques messages, y compris le timestamp Kafka qui représente le temps écoulé depuis l’époque Unix. Défini comme 00:00:00 Temps universel coordonné (UTC) le 1er janvier 1970. Il s’agit d’une façon courante de représenter le temps dans de nombreux systèmes informatiques.
À partir de cette interface, sélectionnez “Appliquer” et “Suivant : Analyse des données”.

Laissez les valeurs par défaut et sélectionnez “Suivant : Analyse du temps”. Laissez également les valeurs par défaut et sélectionnez “Suivant : Transformation, Suivant : Filtre, Suivant : Configuration du schéma” et “Suivant : Partition”. Sur l’écran “Partition”, sélectionnez “heure” comme granularité de segment.

Sur l’écran “Réglages”, sélectionnez “Utiliser le premier offset” comme “True” et “Suivant : Publier”.

Laissez les valeurs par défaut et sélectionnez “Suivant : Modifier la spécification”.

Sur l’écran “Modifier la spécification”, modifiez la configuration des “dimensionsSpec” en utilisant le JSON suivant :
"dimensionsSpec": {
"dimensions": [],
"useSchemaDiscovery": true
},Voici un exemple de spécification de configuration :
Notez que le “dimensionsSpec” est la section où vous ajouteriez généralement les types de données, il contient simplement un tableau de dimensions [] et utilise la détection automatique du schéma avec la valeur “true”.
Après avoir modifié la spécification, sélectionnez “Soumettre”.

Maintenant que la tâche d’ingestion a été configurée et que la source de données a été configurée, nous allons modifier le message Kafka en ajoutant un champ. Décommentez la ligne de code surlignée du code Python montré ci-dessus :
"new_field": "New Field Value"Relancez le code pour créer et envoyer des messages à Kafka. Ensuite, accédez à l’interface de requête depuis la console de Druid et exécutez cette requête :
SELECT * FROM test_topicNotez que dans les résultats de la requête, le “new_field” que nous avons ajouté au message JSON envoyé par le producteur Kafka est inclus sans avoir besoin de modifier la spécification d’ingestion et d’ajouter un schéma.

Dans cet article, nous avons parcouru un guide complet sur l’installation de Druid et Kafka, la définition d’une source de données en continu et la configuration d’une tâche d’ingestion. Nous avons également ajusté les messages publiés par Kafka pour inclure un champ supplémentaire. Cela nous a permis de démontrer la découverte automatique du schéma de Druid en utilisant un scénario réel où les modifications de l’ensemble de données sont gérées de manière transparente, sans intervention humaine.
Cette fonctionnalité innovante donne aux utilisateurs une flexibilité sans précédent, permettant à l’environnement d’évoluer avec des sources de données diverses sans la tâche ardue de la définition et de la maintenance manuelles du schéma. En termes pratiques, cela libère les utilisateurs pour se concentrer davantage sur des tâches telles que l’interprétation des données et l’obtention d’informations précieuses, au lieu d’être absorbés par des tâches administratives. C’est une excellente nouvelle pour tous ceux qui s’intéressent à l’analyse des données en temps réel. La capacité à donner du sens aux données en temps réel avec agilité et précision ouvre de nouvelles possibilités pour transformer les données brutes en informations exploitables.
Pour plus d’informations sur la découverte automatique du schéma avec Apache Druid, veuillez consulter l’article Introduction à la découverte automatique du schéma dans Apache Druid.
Rick Jacobs est un responsable marketing technique senior chez Imply. Il possède une expérience variée acquise chez IBM, Cloudera et Couchbase. Il compte plus de 20 ans d’expérience dans le domaine de la technologie, acquise en occupant des postes dans le développement, le conseil, la science des données, l’ingénierie commerciale et d’autres domaines. Il détient plusieurs diplômes universitaires, dont une maîtrise en science informatique de l’université George Mason. Lorsqu’il ne travaille pas sur la technologie, Rick essaie d’apprendre l’espagnol et poursuit son rêve de devenir un adepte de la plage.