

Crédit image : partner learning camp
Mise à jour le 14 février 2023 avec les dernières informations et ressources.
Qu’on se le dise : Salesforce Flow est l’outil ultime d’automatisation du futur. Flow n’est pas seulement un “outil pour les administrateurs” – c’est le Graal du développement déclaratif qui réunit les développeurs ET les administrateurs en permettant l’utilisation de Lightning Web Components (LWC) et Apex, tout en permettant à l’administrateur d’orchestrer tout cela en un seul endroit. Nous commençons à voir une collaboration unique entre les administrateurs et les développeurs, les deux côtés apprenant quelque chose sur le développement et l’administration.
Dans ce guide, nous aborderons les meilleures pratiques, les “trucs à éviter” et les conseils de conception pour que vos flows évoluent avec votre organisation.
1. Documentez vos flows !
Documenter votre flow permet à la personne suivante, ou à la version future de vous-même qui a oublié, de comprendre l’objectif global du flow. Les concepteurs de flow ne créent pas de solutions à partir de rien – nous avons besoin d’un cas d’utilisation pour résoudre des problèmes complexes, et il est essentiel d’avoir ces indices pour maintenir l’automatisation à long terme.
Décrivez le but du flow
Remplissez ce champ de description ! Quel problème votre flow résout-il ? Veillez à inclure ce que fait votre flow, les objets qu’il utilise et où il est invoqué (comme quelle disposition de page utiliser s’il s’agit d’un flow d’écran, quel processus Process Builder utiliser s’il s’agit d’un flow déclenché automatiquement, etc.). Encore mieux si vous mentionnez où ce flow s’inscrit dans le processus métier et les groupes auxquels il est lié, afin que la personne suivante puisse s’adresser à eux avec des questions. Avez-vous un JIRA ou un ID de story pour le lier à une histoire ? Ajoutez-le dans la description !
Assurez-vous d’une dénomination cohérente des éléments et des variables
Respectez les conventions de dénomination lors de la création de variables et d’éléments dans Flow. Mentionnez dans la description de la variable ce que vous capturez. Un peu de travail préliminaire ira loin pour le “vous” futur ou quelqu’un d’autre qui héritera du flow. Il n’y a pas de bonne ou de mauvaise façon de faire cela ; gardez simplement la cohérence à l’intérieur du flow. Une convention de dénomination populaire s’appelle “CamelCase”. Consultez cet article astucieux du serveur Discord de l’échange Salesforce pour des suggestions de dénominations de flow.
Documentez chaque étape
Assurez-vous d’écrire de courts textes dans chaque étape et expliquez le rôle de chaque élément de Flow et son objectif. Cela permettra à n’importe quel membre de l’équipe de reprendre le travail si nécessaire. C’est particulièrement important lorsque vous utilisez une solution de contournement pour résoudre une limitation de Flow, pour effectuer une fonction plus avancée ou pour appeler un Apex invocable.
2. Exploitez la puissance des actions invoquées
Nettoyez les flows inefficaces avec des actions invoquées – n’ayez pas peur d’utiliser un code réutilisable pour créer des flows élégants et propres. Dans le passé, vous pouviez invoquer Apex à partir de Flow, mais vous deviez pratiquement l’utiliser pour cet objet ou ce type de données. Ces jours sont révolus, Flow prenant désormais en charge des entrées et sorties génériques. Le code générique utilisé dans les actions invoquables amplifiera les capacités de votre Flow – utilisez une seule action pour autant de flows que vous le souhaitez !
Flow est fantastique, mais il a ses limites, en particulier en ce qui concerne les requêtes, les volumes de données importants et le travail avec des collections. Si vous vous retrouvez à créer des boucles dans des boucles, ou à atteindre les limites d’exécution de l’élément, il est temps d’utiliser Apex réutilisable pour vous faciliter la tâche.
Il existe un excellent référentiel d’actions invoquées par Flow appelé “Automation Component Library” – jetez-y un coup d’œil !
3. Utilisez des sous-flows pour des flux plus propres, réutilisables et évolutifs
Prenez ce flow comme exemple pour vous poser la question : “Devrais-je utiliser un sous-flow ?”
Voici quelques cas d’utilisation classiques pour lesquels vous devriez envisager un sous-flow.
- Réutilisation : Si vous faites la même chose plusieurs fois dans votre flow, ou si vous faites la même chose qu’un autre flow, appelez un sous-flow pour le faire à votre place. Le monde du développement appelle cela des “classes Helper”.
- Processus complexes/sous-processus : Si votre flow implique plusieurs processus et une logique de branchement, utilisez un flow principal qui lance d’autres flows secondaires. Par exemple :
- “Gestion des données de contact” – Flow principal qui lance plusieurs processus déconnectés :
- “Associer le contact aux entreprises”
- “Vérifier les données de contact”
- “Gérer les associations du contact”
- “Gestion des données de contact” – Flow principal qui lance plusieurs processus déconnectés :
- Chaos organisationnel : Si votre flow ressemble à celui ci-dessus, vous avez probablement besoin d’un sous-flow (ou de plusieurs) pour comprendre comment tout est lié et donner un sens au processus global.
- Gestion des autorisations : Disons que vous avez un flow d’écran qui s’exécute dans le contexte de l’utilisateur, mais vous devez accéder à un objet système auquel l’utilisateur n’a pas accès. Utilisez un sous-flow ! En utilisant un sous-flow avec des autorisations élevées, vous pouvez accorder temporairement à cet utilisateur ce dont il a besoin pour poursuivre le flow.
Avantages des sous-flows :
- Effectuez des modifications une seule fois au lieu de les répartir en 10 endroits différents.
- Profitez de flows propres, concis et mieux organisés.
- Maintenez un seul endroit pour les comportements de toute l’organisation, comme l’envoi d’un e-mail d’erreur cohérent ou l’affichage d’un même écran d’erreur dans tous les flows (en utilisant la variable $Flow.FaultMessage).
Points à prendre en compte avec les sous-flows :
- Les modifications apportées au sous-flow nécessitent une collaboration et des tests supplémentaires entre les groupes.
- Le débogage peut être délicat avec les sous-flows. Lorsque vous commencez à utiliser des composants Lightning et des actions Apex, vous n’obtenez pas toujours des erreurs détaillées si l’erreur s’est produite dans un sous-flow.
- Trop de sous-flows peut créer une surcharge dans l’expérience utilisateur – n’en abusez pas.
4. N’encombrez pas les flows de logique en dur
Abstraction de la logique
Une excellente façon de ralentir le processus de développement et de réduire l’agilité de votre équipe est de coder en dur toute votre logique à l’intérieur des flows. Lorsque c’est possible, vous devriez stocker votre logique en un seul endroit afin que les outils d’automatisation tels que Apex, les règles de validation et les autres flows puissent également en bénéficier. Vous devriez envisager d’utiliser des métadonnées personnalisées, des paramètres personnalisés ou des libellés personnalisés dans vos flows dans les scénarios suivants.
- Consolidez les données d’application ou d’organisation qui sont référencées à plusieurs endroits.
- Gérez les mappages (par exemple, mappage d’un état à un taux de taxe ou mappage d’un type d’enregistrement à une file d’attente).
- Gérez les informations sujettes à modification ou qui changeront fréquemment.
- Stockez des textes fréquemment utilisés, tels que des descriptions de tâches, des descriptions de discussion ou du contenu de notification.
- Stockez des variables d’environnement (URL ou valeurs spécifiques à chaque environnement Salesforce).
Vous pouvez utiliser des choses comme les libellés personnalisés si vous souhaitez stocker des valeurs simples comme “X jours”, des ID de propriétaire d’enregistrement ou des valeurs qui pourraient changer à l’avenir.
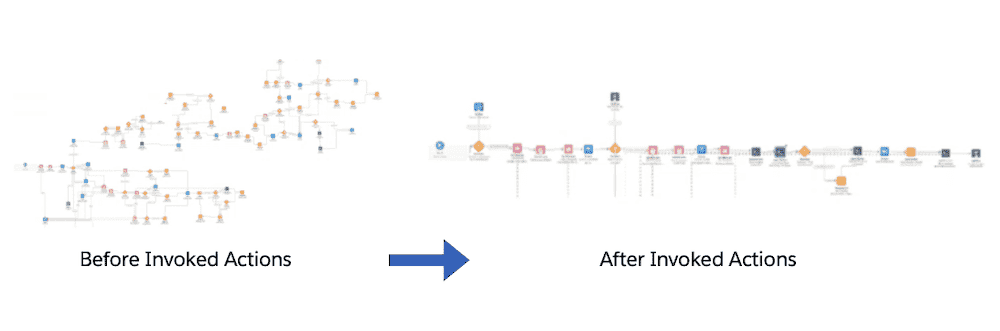
Pour vous donner une idée de la propreté des flows pilotés par les métadonnées personnalisées, jetez un coup d’œil à l’avant et à l’après de ce flow de “Enregistrement de cas après sauvegarde” qui fait correspondre les types d’enregistrement avec les files d’attente. La solution utilise des enregistrements de métadonnées personnalisées qui stockent un nom de développeur de file d’attente, un nom de développeur de type d’enregistrement et le champ “Département” à mettre à jour sur le cas de manière dynamique.
Avant la logique pilotée par des métadonnées personnalisées

Après la logique pilotée par des métadonnées personnalisées

Je vous recommande également vivement de lire l’article de Jennifer Lee sur l’évitement de la logique en dur sur le blog des administrateurs Salesforce.
Flows basés sur les données d’écran
Si vous constatez que votre équipe construit 20 à 30 (ou plus) écrans avec une logique et un contenu en constante évolution, vous pouvez avoir besoin d’un modèle de conception d’écran dynamique basé sur les données d’enregistrement.
Consultez cet excellent article sur UnofficialSF écrit par le vice-président des produits de Salesforce, Alex Edelstein, sur la façon dont vous pouvez créer un flow équivalent à 500 écrans en utilisant uniquement des enregistrements d’objet personnalisés (DiagnosticNode/DiagnosticOutcome) et les fonctionnalités standard de Flow.
Autres liens utiles sur Flow et la logique métier :
- Parcours Trailhead : Utilisation des types de métadonnées personnalisés dans les flows
- Site Salesforce Admins : Compte-rendu du webinar sur l’automatisation avancée avec les flows et les types de métadonnées personnalisés
- Site externe : UnofficialSF : Dreamforce Slides – Flux Flow avancés pour les administrateurs
5. Évitez ces erreurs courantes des constructeurs
Ne pas vérifier les lacunes dans votre logique
Flow est essentiellement une programmation déclarative, ce qui signifie qu’il n’y a pas de limites imposées ! Vous devez prendre en compte tous les scénarios lors de la construction de votre flow. Cela signifie planifier les cas où ce que vous recherchez pourrait ne pas exister !
Ajoutez toujours un élément de décision après un élément de recherche de données pour vérifier si aucun résultat n’est retrouvé si vous prévoyez d’utiliser les résultats ultérieurement dans votre flow. Ajoutez directement après la recherche un test de décision “Si null égal à faux” pour vérifier la variable créée dans l’élément “Rechercher des enregistrements”. Ce test correspond à votre vérification de “null” si vous codez.
Pourquoi voulons-nous faire cela ? Imaginez que l’intégralité de votre flow repose sur une seule hypothèse – un enregistrement que vous recherchez existe réellement dans votre organisation. Si quelque chose se passe et que nous ne trouvons pas réellement cet enregistrement tôt dans le flow, votre flow tentera toutes sortes d’opérations et vous pourriez vous retrouver avec des conséquences involontaires, comme des erreurs, des données incorrectes ou une mauvaise expérience utilisateur.
Certaines actions invoquées ou composants d’écran peuvent renvoyer une collection “vide” qui n’est pas considérée comme “null”. Un exemple classique est le composant “Téléchargement de fichier” intégré qui renvoie une collection de texte vide s’il n’y a pas de fichier téléchargé. Si vous rencontrez ce problème, la manière la plus simple de prendre une décision consiste à attribuer à la collection un nombre à l’aide d’un élément d’assignation et à prendre votre décision en fonction de la valeur numérique.
Ne pas coder en dur les ID
Flow ne vous permet pas encore de faire référence au nom du développeur d’objets tels que le type d’enregistrement, les files d’attente ou les groupes publics dans certaines parties de l’interface utilisateur, mais cela ne signifie pas que vous devez coder en dur l’ID.
Construction d’un flow déclenché par un enregistrement ? Utiliser une formule pour vos conditions d’entrée vous permettra de faire référence au nom du développeur d’enregistrement dans vos conditions de déclenchement.
Dans les scénarios où vous ne pouvez pas faire directement référence au nom du développeur, utilisez les résultats d’un élément “Obtenir des enregistrements”, d’un libellé personnalisé ou de métadonnées personnalisées. Cela vous évitera des problèmes lors du déploiement dans vos environnements, car les ID de type d’enregistrement et autres identifiants uniques peuvent différer entre les environnements.
Par exemple, vous pouvez créer une recherche d’enregistrements sur l’objet “RecordType”. Ensuite, dans vos conditions, spécifiez le “DeveloperName” et le champ “Object”, et stockez l’ID de l’enregistrement trouvé (ID du type d’enregistrement) pour une utilisation ultérieure dans votre flow.
Besoin de faire référence à une file d’attente ou à un groupe public ? Effectuez une recherche d’enregistrements en utilisant le “DeveloperName” de la file d’attente sur l’objet “Group” au lieu de coder en dur l’ID.
Apprenez à vous familiariser avec la documentation détaillée fournie par Salesforce sur les objets de configuration tels que “Group”, “RecordType” et “ContentDocumentLink”. Comprendre le modèle de données de Salesforce vous rendra un administrateur et un concepteur de Flow infiniment plus puissant.
Ne pas être prudent lors des boucles
Il y a trois préoccupations principales lors des boucles, qui concernent les limites d’éléments, les limites SOQL et l’utilisation de formules complexes.
[CONSEILS MIS À JOUR, février 2023] [Note : La limite d’itérations d’éléments a été supprimée dans la version Spring ’23, mais nécessite que les flows s’exécutent sur les versions d’API 57 ou supérieures. Bien que nous ayons supprimé la limite d’éléments, vous devez toujours vous familiariser avec les limites générales du système telles que les délais de temps d’utilisation du processeur et les limites SOQL.]- Méfiez-vous de la limite des “éléments exécutés” – chaque fois que Flow atteint un élément, cela compte comme une “exécution d’élément”. À partir de Spring ’21, il y a actuellement 2000 exécutions d’éléments autorisées par entretien de Flow. Considérez un scénario où vous exécutez une boucle sur plus de 1500 contacts.
Dans votre boucle, vous avez votre élément “Boucle” (1), un élément “Décision” (2), une étape d’assignation pour définir certaines variables dans votre enregistrement bouclé (3) et une étape dans laquelle vous ajoutez cet enregistrement à une collection à mettre à jour, créer ou supprimer ultérieurement dans le flow (4). Chacun de ces quatre éléments dans la boucle comptera pour votre limite d’exécution. Cela signifie que votre boucle sur 1500 enregistrements aura 6000 éléments exécutés, ce qui dépasse largement la limite d’itération.
Lorsque vous approchez de cette limite, vous devrez probablement faire preuve de créativité pour arrêter la transaction ou rendre votre flow plus efficace en utilisant des actions invoquées. Gardez à l’esprit que la transaction se termine lorsqu’un élément “Pause” est atteint ou, dans les flows d’écran, lorsqu’une action d’écran/action locale est affichée.
- Ne mettez pas d’éléments de manipulation de données (DML) à l’intérieur d’une boucle (par exemple, Obtenir des enregistrements, Mettre à jour, Supprimer, Créer) à moins que vous ne soyez sûr à 100 % que la portée ne déclenchera pas de limites gouverneur. Cela n’est généralement possible que dans les flows d’écran, lorsque vous bouclez sur un petit sous-ensemble d’enregistrements. Utilisez plutôt Apex invoquable si vous avez besoin d’effectuer une logique complexe sur une collection.
Dans Winter ’23, nous avons introduit les nouveaux opérateurs “In” et “Not In” afin que vous puissiez créer des flows plus performants et évolutifs pour éviter les requêtes dans les boucles qui entraînent des limites gouverneur.
- Faites attention aux variables de formule complexes – Selon le “Record-Triggered Automation Decision Guide” : “Le moteur de formule de Flow présente sporadiquement des performances médiocres lors de la résolution de formules extrêmement complexes. Ce problème est exacerbé dans les cas d’utilisation par lots car les formules sont actuellement compilées et résolues de manière séquentielle pendant l’exécution. Nous évaluons activement des options de compilation de formules adaptées aux lots, mais la résolution de formules sera toujours séquentielle. Nous n’avons pas encore identifié la cause première de la mauvaise performance de résolution de formules.“
Ne pas créer de chemins d’erreur
Avant de construire votre flow, réfléchissez à ce qui devrait se passer en cas d’erreur. Qui devrait être informé ? Doit-il générer un enregistrement de journal ?
L’une des erreurs les plus courantes que commet un concepteur de flow naissant est de ne pas créer de chemins d’erreur. Un chemin d’erreur est conçu pour gérer les erreurs rencontrées par un flow, en indiquant ce qu’il faut faire – pensez-y comme à une gestion des exceptions. Les deux utilisations les plus courantes sont l’affichage d’un écran d’erreur pour les flows basés sur des écrans ou l’envoi d’une alerte par e-mail contenant le message d’erreur à un groupe de personnes.
J’aime généralement transférer les erreurs vers des sous-flows qui gèrent les erreurs pour moi ; ainsi, si jamais j’ai besoin de modifier un aspect du chemin d’erreur, je n’ai qu’à le faire à un seul endroit pour tous mes flows.
Pour les implémentations de qualité entreprise, envisagez d’utiliser une stratégie de journalisation complète dans laquelle les flows enregistrent les erreurs au même endroit que votre code Apex. Vous pouvez utiliser un outil open source comme Nebula Logger pour écrire dans un objet de journal personnalisé lorsque votre flow échoue, ou laissez simplement un sous-flow avec des autorisations élevées créer des enregistrements de journal pour vous si vous n’avez pas besoin de quelque chose de fantaisiste.
6. Flows d’écran : tenez compte du “contexte” du flow
Faites toujours attention au contexte dans lequel votre flow s’exécute lors de l’utilisation d’un flow d’écran. Si vous faites en sorte qu’un flow d’écran s’exécute dans le contexte de l’utilisateur, n’allez pas créer un élément “Obtenir des enregistrements” sur un objet que l’utilisateur ne peut pas voir, comme des champs spécifiques à l’administrateur sur l’objet “Utilisateur” ou des objets de configuration.
Testez votre flow en tant qu’utilisateur cible et en tant qu’utilisateurs qui ne sont pas dans votre public cible. Vous ne voulez pas que les utilisateurs aient une expérience difficile dans un flow qui ne leur était pas destiné. Utilisez des autorisations spécifiques aux flows ou des autorisations personnalisées attribuées via des jeux de permissions pour gérer l’accès au flow si vous avez besoin d’un contrôle granulaire. Besoin de contrôler l’accès à l’ensemble du flow ? Utilisez des autorisations de flow. Besoin de contrôler l’accès à des parties spécifiques d’un seul flow ? Vous pouvez faire référence à une permission personnalisée attribuée à l’utilisateur en cours d’exécution en utilisant la variable $Permission dans un élément de décision ou des critères de visibilité de champ conditionnels.
Si vous avez vraiment besoin de récupérer des champs ou des enregistrements au niveau du système (comme les enregistrements de métadonnées personnalisées), utilisez des sous-flows avec des autorisations système élevées pour effectuer des tâches clés que vous pouvez appeler dans l’ensemble des flows.
Tout ne respecte pas le contexte système ! Les composants Lightning tels que Lookup et File Upload, ainsi que les champs d’enregistrement de Dynamic Forms for Flow, ne respectent pas le contexte système.
7. Évaluez votre stratégie d’automatisation déclenchée
Chaque objet devrait avoir une stratégie d’automatisation basée sur les besoins de l’entreprise et de l’équipe Salesforce qui la soutient. En général, vous devriez choisir un outil d’automatisation par objet. L’un des nombreux scénarios inévitables de vieilles organisations est d’avoir des déclencheurs Apex mélangés aux flows/des processus déclenchés automatiquement ou, plus récemment, des processus déclenchés avec des record-triggered flows. Cela peut entraîner divers problèmes, notamment :
- Performance médiocre
- Résultats inattendus en raison de l’incapacité de contrôler l’ordre des opérations dans “la pile”
- Augmentation de la dette technique avec des administrateurs/développeurs qui ne collaborent pas
- Dette documentaire
Une approche courante consiste à séparer les activités DML et à les décharger dans Apex, et à laisser les outils déclaratifs gérer les activités non-DML telles que les alertes par e-mail et les alertes intégrées à l’application – veillez simplement à vous assurer qu’aucun de vos Apex ne se chevauche. Nous sommes encore très loin de la phase “Far West” des record-triggered flows alors que les architectes et les administrateurs cherchent la meilleure façon de les intégrer dans leurs systèmes.
J’ai vu certaines organisations plus audacieuses utiliser des gestionnaires de déclencheurs pour déclencher des flows déclenchés automatiquement (voir le framework de Mitch Spano comme exemple). C’est une excellente façon de faire collaborer les administrateurs et les développeurs.
Voici un excellent article sur les pièges de la création de différents types d’automatisation par Mehdi Maujood.
En général, vous devriez vous éloigner de Process Builder et surtout des Workflow Rules, car les deux seront abandonnés. Rappelez-vous qu’à partir de Winter ’23, vous ne pouvez plus créer de nouvelles Workflow Rules.
Structurez le nombre de flows sur un objet en fonction de vos besoins métier
Finie la recommandation “Un Process Builder par objet” de l’époque de Process Builder ; cependant, cela ne signifie pas que vous devriez créer des centaines de flows sur un objet. Gardez le nombre de flows déclenchés par enregistrement à un niveau raisonnable en tenant compte de vos besoins métier. Bien qu’il n’y ait pas vraiment de nombre idéal, une bonne règle de base est de séparer vos flows par fonction métier ou rôle afin de réduire au maximum les risques de conflits. Vous pouvez également prendre en compte le nombre d’administrateurs ou de développeurs qui doivent maintenir vos flows. Il est historiquement difficile de maintenir de gros flows monolithiques entre les mains de nombreux intervenants, ce qui signifie qu’il est peut-être plus facile de construire plusieurs flows plus petits et plus faciles à maintenir, ordonnés par Flow Trigger Explorer et avec des conditions d’entrée fines.
Référez-vous à la merveilleuse session Automate This! dans la section des liens connexes au bas de cet article de blog où nous abordons une variété de modèles de conception pour les flows déclenchés par enregistrement.
Utilisez des critères d’entrée
Soyez précis avec vos critères d’entrée – vous ne voulez pas exécuter d’automatisation sur des modifications d’enregistrements qui ne seront pas utilisées dans vos flows ! L’équipe Flow a considérablement amélioré le coût de calcul des flows qui ne répondent pas aux critères d’entrée, ce qui était un problème majeur pour Process Builder. Cela, associé aux problèmes d’ordre d’exécution, a éliminé l’un des derniers obstacles à avoir trop d’automatismes sur un objet.
En ce qui concerne les indicateurs de performance et les performances, utilisez toujours des flows “avant sauvegarde” lorsque vous mettez à jour le même enregistrement qui a déclenché l’automatisation. Selon le “Architect’s Guide to Record-Triggered Automation”, les flows “avant sauvegarde” sont NETTEMENT plus rapides que les flows “après sauvegarde” et sont presque aussi performants que l’Apex.
8. Prévoyez une possibilité de contourner vos flows pour les chargements de données et l’alimentation des environnements sandbox
Ce n’est pas une bonne pratique spécifique à Flow, mais il est bon d’inclure une possibilité de contourner les déclencheurs et l’automatisation déclarative. Grâce à une telle stratégie de contournement, vous pouvez désactiver toutes les automatisations pour un objet (ou globalement) si vous devez importer en bloc des données. C’est une méthode courante pour éviter les limites gouverneur lors de l’alimentation d’un nouvel environnement sandbox ou du chargement d’une grande quantité de données dans votre org.
Il existe de nombreuses façons de le faire – il suffit d’être cohérent dans vos automatisations et de veiller à ce que vos contournements soient tous regroupés (comme un type de métadonnées personnalisé ou une autorisation personnalisée).
9. Comprenez comment les flows planifiés affectent les limites gouverneur
La sélection de votre plage d’enregistrements au début de la configuration d’un flow planifié aura de grandes répercussions sur les limites gouverneur dudit flow. Lorsque nous parlons de “configuration de la plage”, nous nous référons à cet écran où nous sélectionnons l’objet et les conditions de filtrage :
Lors de la spécification de la portée d’enregistrement dans le départ du flow (ci-dessus)

Lors de la spécification de la portée dans le flow (action invoquée, obtenir des enregistrements)
Les limites seront plus alignées avec ce à quoi vous êtes habitué avec un seul flow, c’est-à-dire qu’un seul entretien de flow sera créé pour le flow au lieu d’un par enregistrement. Si vous empruntez cette voie, ne spécifiez pas une portée pour le même ensemble d’enregistrements (re : la capture d’écran ci-dessus) ! Si vous le faites, le flow s’exécutera pour N² enregistrements, atteignant rapidement les limites.
Utilisez cette approche lorsque vous avez besoin d’un contrôle plus strict sur les limites et que vous souhaitez invoquer Apex qui pourrait impliquer une requête SOQL ou un traitement complexe.
Dans ce scénario, si vous avez une recherche de “Obtenir des enregistrements” qui renvoie 800 enregistrements, Flow ne va pas essayer de regrouper ces enregistrements. Gardez à l’esprit que l’utilisateur exécuté est toujours un utilisateur de Processus automatisé, il présente donc certaines particularités, comme l’impossibilité de voir tous les “CollaborationGroups” (groupes Chatter) ou les bibliothèques.
Double utilisation : encore une fois, NE sélectionnez PAS une portée d’enregistrement et effectuez une étape “Obtenir des enregistrements” pour le même groupe d’enregistrements ; vous multiplierez efficacement la quantité de travail que votre flow doit effectuer par N² et atteindrez rapidement les limites.
Quel chemin dois-je choisir ?
Il n’y a pas de bonne ou de mauvaise réponse quant à la voie à suivre. Il y a moins de moyens contrôlés par l’utilisateur pour contrôler les limites associées à la première voie – vous ne pouvez pas spécifier la taille des lots ou le nombre total d’enregistrements dans la plage. Donc, si vous avez besoin d’un contrôle plus strict sur les limites, il est peut-être préférable de créer une action invoquable et de spécifier votre plage de cette manière. Ou tout simplement, ne faites pas cela dans un flow planifié – utilisez une tâche planifiée avec l’Apex.
Il y a aussi certains cas d’utilisation impliquant des dates d’enregistrement où vous pourriez configurer un chemin planifié sur un flow déclenché par un enregistrement. Les chemins planifiés ont des limites gouverneur plus flexibles et permettent également de configurer des tailles de lots configurables, ce qui peut offrir un compromis entre l’Apex et les flows déclenchés par planification.
Pour en savoir plus sur les considérations des flows planifiés, consultez la documentation officielle : “Schedule-Triggered Flow Considerations”.
10. Consultez la liste de contrôle !
Vous êtes prêt à construire d’excellents flows ! Voici une liste de contrôle pratique qui s’applique à chaque flow.
- Éléments et descriptions documentés : assurez-vous que votre flow a une description solide, une convention de dénomination décente pour les variables, et des descriptions pour les éléments de Flow qui pourraient ne pas avoir de sens si vous les revisitez dans 6 mois.
- Vérifications de Null/Vide : n’oubliez pas de vérifier les résultats Null ou Vides dans les éléments de décision avant d’agir sur un ensemble d’enregistrements. Ne supposez pas un parcours sans problème – pensez à tous les scénarios possibles !
- IDs codés en dur : ne codez pas en dur les IDs pour des choses comme les IDs de propriétaire, les IDs de file d’attente, les groupes ou les IDs de type d’enregistrement. Faites une recherche d’enregistrements pour l’objet correspondant en utilisant le “DeveloperName”. Si vous créez des critères dans une condition d’entrée, vous pouvez faire référence aux champs “DeveloperName” (nom API) avec une formule.
- Logique codée en dur : ne codez pas en dur des logiques de référence dans une décision qui pourraient changer fréquemment, comme les IDs de file d’attente, les IDs de propriétaire ou les nombres (comme un pourcentage de réduction). Utilisez des libellés personnalisés et des métadonnées personnalisées !
- Boucles imbriquées excessives et “astuces” : étirez-vous-vous aux limites de performance de Flow alors que du code serait plus approprié ? Utilisez des actions invoquables génériques construites par vos développeurs, ou utilisez des composants de la Bibliothèque de composants d’automatisation ou d’autres contributions open source.
- Boucler sur de grands volumes de données : ne bouclez pas sur de grandes collections d’enregistrements qui pourraient déclencher la limite d’éléments de Flow (actuellement de 2 000) ou les limites CPU Apex.
- Vérification de la sécurité des enregistrements et des champs et contexte de Flow : ne supposez pas que votre utilisateur peut voir et faire tout ce que vous avez conçu si vous construisez un flow d’écran. Testez vos flows à la fois sur votre public cible et sur des utilisateurs qui ne sont pas dans votre public cible.
- Manipulation des données dans une boucle : ne mettez pas d’éléments de création/mise à jour/suppression à l’intérieur d’une boucle dans un flow déclenché automatiquement ou un flow déclenché par enregistrement. Utilisez les nouveaux opérateurs “In/Not In” lorsque vous le pouvez !
- Erreurs de Flow : Que voulez-vous qu’il se passe lorsque le flow rencontre une erreur ? Qui doit être informé ? Utilisez ces chemins d’erreur !
- Contournement de l’automatisation : Votre flow déclenché automatiquement ou par enregistrement a-t-il un contournement basé sur des paramètres personnalisés ou des métadonnées personnalisées en place ?
Allez construire !
Si vous êtes arrivé jusqu’ici, félicitations ! Vous êtes bien parti pour devenir un pro de Flow et vous n’êtes pas seul. Rejoignez la communauté Salesforce Automation Trailblazer pour entrer en contact avec d’autres administrateurs Salesforce du monde entier. La communauté est un excellent endroit pour en savoir plus sur les flows que les autres administrateurs construisent, pour connaître les dernières mises à jour des chefs de produit et pour poser des questions sur Flow. J’espère que ce guide vous a été utile et j’ai hâte de voir tous les flows que vous allez construire !
Ressources :
- Architect’s Guide to Record-Triggered Automation
- Salesforce Automation Trailblazer Community
- UnofficialSF
- Automation Component Library
- Advanced Logging with Nebula Logger
- Flow Naming Conventions | SFXD Wiki