
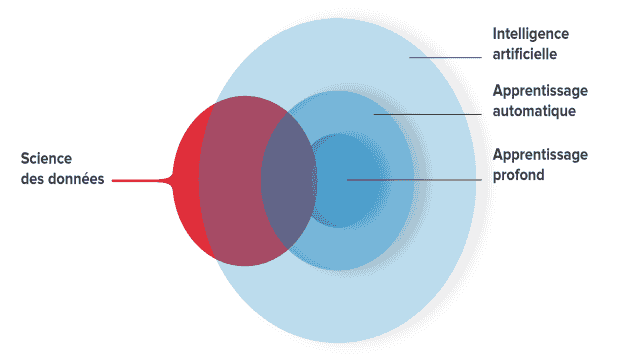
L’apprentissage automatique (Machine Learning) est un domaine essentiel de l’intelligence artificielle et de la science des données (Analytics and Data Science).

Il existe différents types d’apprentissage automatique : supervisé, non-supervisé et par renforcement.
L’apprentissage supervisé
Dans ce type d’apprentissage, nous disposons de données d’entrée (features) ainsi que des résultats attendus (label). Il nous permet de faire des prédictions basées sur un modèle. Ce dernier est construit à partir de données historiques et de l’algorithme choisi.
L’apprentissage supervisé répond à deux types de questions :
- Classification : “quelle classe ?”
- Régression : “combien ?”
L’apprentissage non-supervisé
Lors de cette phase d’apprentissage, nous avons toujours des features, mais aucune étiquette (label), car le but n’est pas de prédire quelque chose.
À partir des données historiques, nous cherchons à découvrir les structures et les modèles qu’elles contiennent. Il est cependant essentiel de valider les conclusions obtenues avec des experts du domaine.
L’apprentissage non-supervisé est souvent utilisé pour l’identification de structures et de modèle dans les données. Il peut également être utile pour l’ingénierie des caractéristiques (Feature Engineering) lors de la préparation des données pour l’apprentissage supervisé.
L’apprentissage par renforcement
Dans ce type d’apprentissage, nous commençons avec un agent (un algorithme) qui doit choisir parmi différentes actions. Selon l’action choisie, l’agent reçoit un retour de l’environnement, qu’il s’agisse d’un humain dans certaines situations ou d’un autre algorithme. Ce retour peut prendre la forme d’une récompense pour un choix judicieux ou d’une pénalité pour une action inappropriée. L’agent apprend ainsi quelle stratégie ou quel choix d’actions maximise les récompenses cumulées.
L’apprentissage par renforcement est souvent utilisé dans le domaine de la robotique, de la théorie des jeux et des véhicules autonomes.
Les principales étapes de l’apprentissage automatique sont les suivantes :
La préparation des données
- Récolte des données : collectez toutes les données nécessaires pour l’apprentissage automatique et assurez-vous de les regrouper dans un seul tableau consolidé.
- Réconciliation (Data Wrangling) : préparez les données pour les rendre exploitables par les algorithmes d’apprentissage automatique.
- Nettoyage des données : identifiez les valeurs nulles, les données manquantes et les doublons. Remplacez les valeurs nulles et les données manquantes par d’autres valeurs ou supprimez-les. Assurez-vous également de ne pas avoir de doublons.
- Décomposition des données : les colonnes de texte peuvent contenir plusieurs informations. Découpez-les en plusieurs colonnes dédiées si nécessaire. Si certaines colonnes représentent des catégories, convertissez-les en colonnes de type catégorie.
- Agrégation de données : regroupez certaines informations lorsque cela est pertinent.
- Mise à l’échelle (Data Scaling) : assurez-vous que toutes les données sont à la même échelle, si ce n’est pas déjà le cas. La mise à l’échelle ne s’applique pas aux labels ou aux colonnes de catégories. Elle est nécessaire lorsque les features ont une grande variation dans leurs plages de valeurs.
- Mise en forme et transformation (Data Shaping & Transformation) : de catégoriel à numérique.
- Enrichissement des données : parfois, il est nécessaire d’enrichir les données existantes avec des données externes afin de fournir à l’algorithme davantage d’informations pour améliorer le modèle. Par exemple, des données économiques ou météorologiques peuvent être utilisées.
L’ingénierie des caractéristiques (Feature Engineering)
- Visualisez l’ensemble de vos données pour identifier des liens entre les colonnes. À l’aide de graphiques, vous pouvez observer les features les unes à côté des autres et détecter les liens entre elles, ainsi qu’entre les features et les labels.
- Les liens entre les features permettent de déterminer si une feature donnée dépend directement d’une autre. Dans ce cas, il se peut que vous n’ayez pas besoin des deux features.
- Les liens entre une feature et le label permettent de voir si une feature a un fort effet sur le résultat.
- Parfois, vous devrez générer de nouvelles features à partir de celles existantes, notamment en cas de classification où l’algorithme choisi a du mal à différencier correctement les classes.
- Si vous vous retrouvez avec un grand nombre de colonnes, vous devrez choisir les features à utiliser. En cas de milliers de colonnes potentielles, une réduction dimensionnelle peut être nécessaire. L’analyse en composantes principales (ACP) est une technique couramment utilisée dans ce cas. L’ACP est un algorithme non-supervisé qui utilise les colonnes existantes pour générer de nouvelles colonnes, appelées composantes principales, qui peuvent être utilisées par la suite dans l’algorithme de classification.
Le choix de l’algorithme
À cette étape, vous pouvez commencer à entraîner les algorithmes, mais avant cela :
- Divisez votre ensemble de données en trois parties : entraînement, test et validation.
- Les données d’entraînement sont utilisées pour entraîner le ou les algorithmes choisis.
- Les données de test sont utilisées pour évaluer les performances du modèle.
- Les données de validation ne sont utilisées qu’à la fin du processus et sont rarement examinées pour éviter d’introduire un biais dans les résultats, sauf si nécessaire.
- Choisissez le ou les algorithmes pertinents.
- Essayez différentes combinaisons de paramètres pour les algorithmes et comparez les performances des résultats.
- Utilisez la procédure des hyperparamètres (Grid-Search en Python, par exemple) pour tester de nombreuses combinaisons et trouver celle qui donne les meilleurs résultats. Évitez les combinaisons manuelles.
- Sauvegardez votre modèle une fois que vous êtes raisonnablement satisfait, même s’il n’est pas parfait. Il est possible que vous ne retrouviez jamais la combinaison qui vous a permis d’obtenir ce modèle.
- Continuez à expérimenter avec de nouveaux modèles et des paramètres différents si les résultats ne sont pas satisfaisants. Vous pouvez revenir aux hyperparamètres ou revoir les features à inclure. Il se peut également que vous deviez revoir l’état de vos données et vérifier s’il y a des problèmes de normalisation, de régularisation, d’échelle ou de valeurs aberrantes.
Lorsque vous vous lancez dans un processus d’apprentissage automatique, gardez à l’esprit qu’il est possible que vos données ne permettent pas d’obtenir de meilleurs résultats que ceux obtenus avec les méthodes classiques déjà en place. Cependant, ce processus vous permettra de découvrir des informations intéressantes lors de l’analyse des données.
(*) Modèle : résultat obtenu en analysant les données avec un algorithme et une combinaison spécifique de paramètres. On suppose que le modèle est une fonction mathématique y = f(x), où x représente les features, y représente le label, et f(x) représente le modèle lui-même.