
Elasticsearch, c’est quoi ? C’est un outil de recherche basé sur la plateforme Apache Lucene. Il offre un moteur de recherche distribué avec une interface web HTTP prenant en charge les données JSON.
Développé en Java et distribué sous licence Apache, Elasticsearch est un moteur de recherche puissant et polyvalent.
Comprendre Elasticsearch en détail (ES)
- Elasticsearch est un moteur de recherche.
- Elasticsearch est basé sur Apache Lucene.
- Elasticsearch fonctionne comme un serveur web, permettant une recherche en temps réel via le protocole RESTful.
- Elasticsearch possède des capacités d’analyse et de statistiques de données.
- Elasticsearch s’exécute sur son propre serveur et communique via RESTful, ce qui le rend indépendant du client et du système d’exploitation utilisés. Son intégration dans votre système est donc facile, il vous suffit d’envoyer une requête HTTP pour obtenir des résultats.
- Elasticsearch est un système distribué et possède une excellente capacité d’évolutivité horizontale. Vous pouvez ajouter des nœuds et il s’auto-évolutera pour vous.
- Elasticsearch est une source ouverte développée en Java.
Les grandes entreprises qui utilisent Elasticsearch
- Wikimedia
- athenahealth
- Adobe Systems
- StumbleUpon Mozilla
- Amadeus IT Group
- Quora
- Foursquare
- Etsy
- SoundCloud
- GitHub
- FDA
- CERN
- Stack Exchange
- Center for Open Science
- Reverb
- Netflix
- Pixabay
- Motili
- Sophos
- Slurm Workload Manager
Comment fonctionne Elasticsearch ?

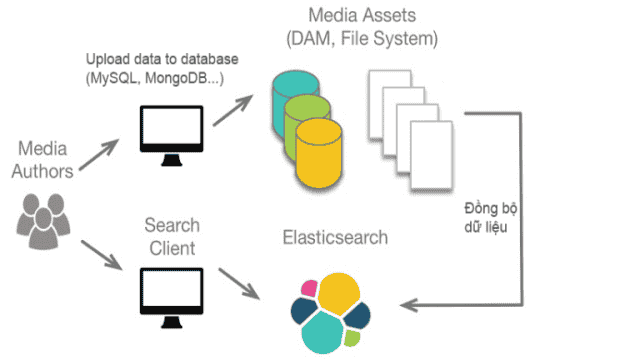
Après avoir compris ce qu’est Elasticsearch, nous allons examiner comment il fonctionne. Il s’agit d’un serveur dédié à la “recherche” de données. Elasticsearch fonctionne sur un port (par défaut local : 9200). Il est possible d’utiliser Elasticsearch comme base de données principale, mais cela est rarement fait car chaque élément a un rôle spécifique.
Elasticsearch n’est pas très performant pour les opérations CRUD, il est donc généralement utilisé en parallèle avec une base de données principale (SQL, MySQL, MongoDB, etc).
Pourquoi utiliser Elasticsearch ?
Pourquoi utiliser Elasticsearch lorsque vous pouvez utiliser la commande LIKE SQL pour la recherche de texte ?
Si vous recherchez avec la requête LIKE “%one%”, les résultats incluront tous les mots contenant “one”. Par exemple : “phone”, “zone”, “money”, “alone”, etc. Cela ne donne pas les résultats souhaités.
En revanche, avec Elasticsearch, en tapant “one”, seule la correspondance exacte “one” sera renvoyée. La requête LIKE ne peut pas rechercher des mots avec des accents. Par exemple, si vous recherchez LIKE “co” pour le mot “côté”, vous n’obtiendrez pas les résultats exacts. En termes de performance, Elasticsearch est plus efficace. La requête LIKE effectue une recherche de texte intégral sans utiliser d’index, ce qui signifie que plus le volume de données est important, plus la recherche est longue. En revanche, Elasticsearch “indexe” les champs sélectionnés pour la recherche.
Intéressé par les emplois offrant un salaire élevé pour les API RESTful ? Pensez à les consulter.
Les concepts clés à connaître
1. Document dans Elasticsearch
Un document est un objet JSON contenant des données. Il s’agit de l’unité d’information de base dans Elasticsearch. Fondamentalement, c’est la plus petite unité de stockage des données dans Elasticsearch.
2. Index
L’index est un concept familier pour ceux qui utilisent déjà MySQL. Cependant, dans Elasticsearch, l’index est totalement différent de celui de MySQL.
Dans Elasticsearch, il utilise une structure appelée “index inversé”. Elle est conçue pour permettre une recherche de texte intégral. Son fonctionnement est assez simple. Les textes sont divisés en mots significatifs, puis ils sont mappés pour voir à quel document chaque mot appartient. Selon le type de recherche, des résultats spécifiques sont renvoyés.
Par exemple, voici deux textes spécifiques :
- The quick brown fox jumped over the lazy dog
- Quick brown foxes leap over lazy dogs in summer
Pour créer un index inversé, nous divisons d’abord le contenu de chaque document en mots distincts (que nous appelons termes), créons une liste triée de tous les termes uniques, puis répertorions les documents dans lesquels chaque terme apparaît. Le résultat est le suivant :
| Terme | Doc_1 | Doc_2 |
|---|---|---|
| Quick | X | |
| The | X | |
| Brown | X | X |
| Dog | X | |
| Dogs | X | |
| Fox | X | |
| Foxes | X | |
| In | X | |
| Jumped | X | |
| Lazy | X | X |
| Leap | X | |
| Over | X | X |
| Quick | X | |
| Summer | X | |
| The | X | |
| – | – | – |
Maintenant, si nous voulons rechercher le terme “quick brown”, nous n’avons qu’à rechercher les documents dans lesquels chaque terme apparaît ou non. Le résultat est le suivant :
| Terme | Doc_1 | Doc_2 |
|---|---|---|
| Brown | X | X |
| Quick | X | – |
| Total | 2 | 1 |