
5 décembre 2022, par Alex Woodie
La commercialisation d’Internet a déclenché une série de développements imprévisibles dans le monde de l’informatique. L’un d’entre eux est la prolifération des applications Web, chacune avec son propre silo de données, ce qui crée le chaos dans la gestion des données et la gouvernance des données. Les architectes d’applications cherchent maintenant à maîtriser ce chaos grâce à de nouvelles architectures d’infrastructure, notamment le maillage de données et le tissu de données.
Alors que la transformation numérique suscite l’espoir chez les entreprises qu’elles peuvent elles aussi bénéficier des avancées en matière d’analyse, d’apprentissage automatique et d’IoT, les données dans la plupart des entreprises sont dans un tel état de désordre que, dans la plupart des cas, c’est plus proche d’un rêve lointain que d’une véritable possibilité.
Les tissus de données et les maillages de données sont deux nouvelles façons dont les entreprises cherchent à trouver une solution aux problèmes de gestion et de gouvernance des données qui affectent les entreprises modernes axées sur les données.
Il existe certaines similitudes entre le maillage de données et le tissu de données, mais il y a aussi des différences importantes. Examinons chaque concept, puis voyons comment IBM i pourrait s’intégrer à chacun d’eux.
Tissu de données
Le concept d’un tissu de données a été conçu pour la première fois au milieu des années 2000 comme un moyen d’unifier la collection disparate d’outils que les ingénieurs de bases de données et d’autres utilisent pour gérer les données dans une entreprise. Ces outils comprennent l’accès aux données, la découverte, la sécurité, l’intégration, la gouvernance, la lignée et l’orchestration des données.
Au lieu de laisser chaque équipe d’application fixer ses propres règles régissant des éléments tels que l’accès aux données et la sécurité, une entreprise adoptant un tissu de données (parfois appelé plan de données) aura un seul outil ou une suite d’outils communs pour appliquer l’accès et la sécurité sur l’ensemble de ses systèmes. Il s’agit d’une technique fédérée qui vise l’uniformité des règles et des actions d’application, qui sont appliquées aux systèmes transactionnels (comme IBM i), ainsi qu’aux systèmes opérationnels et analytiques fonctionnant sur site et dans le cloud.
Un élément clé du tissu de données est que les utilisateurs peuvent interagir avec lui de manière libre-service. Une fois que les outils impliqués dans le tissu de données sont configurés (généralement de manière basée sur du code faible ou sans code), ils peuvent ensuite être appliqués au niveau logique via les métadonnées.
Les entreprises peuvent bricoler leur propre tissu de données en utilisant des outils disparates, ou elles peuvent acheter une suite de tissu de données prête à l’emploi auprès de fournisseurs tels qu’Informatica et Talend, qui ont tous deux soutenu les systèmes IBM mainframe et midrange avec leurs solutions ETL (la qualité des données et l’existence d’un ensemble commun de sémantique des données sont un autre aspect important du tissu de données).
IBM est optimiste quant aux tissus de données et vend une offre de tissu de données appelée Cloud Pak for Data qui peut être déployée dans le cloud ou en local. Cette offre basée sur OpenShift comprend une variété d’outils pour gérer les différents besoins d’un tissu de données, notamment un catalogue de données, une réplication des données et des connexions aux bases de données, y compris Db2 et des bases de données tierces. La société vient de publier Cloud Pak for Data 4.6 ; vous pouvez consulter le document “Quoi de neuf” ici.
Dans son livre blanc intitulé “L’architecture du tissu de données offre des avantages instantanés”, IBM explique comment les tissus de données résolvent les problèmes de gestion des données hybrides en “trouvant un équilibre entre la décentralisation et la mondialisation en agissant comme un tissu connectif virtuel entre les points de terminaison de données”.
Inderpal Bhandari, directeur mondial des données d’IBM, est également un grand partisan des tissus de données. “Chez IBM, j’ai vu de première main la valeur qu’une architecture de tissu de données apporte en termes de simplification de l’accès aux données”, a-t-il écrit récemment dans un article du magazine CDO.
“Un tissu de données peut, par exemple, utiliser l’intelligence artificielle pour apprendre en continu les schémas de transformation des données afin d’automatiser les pipelines de données, ce qui facilite la recherche de données et applique automatiquement la gouvernance et la conformité”, poursuit M. Bhandari. “Il améliore considérablement la productivité, accélère la création de valeur pour une entreprise et simplifie les rapports de conformité”.
Maillage de données
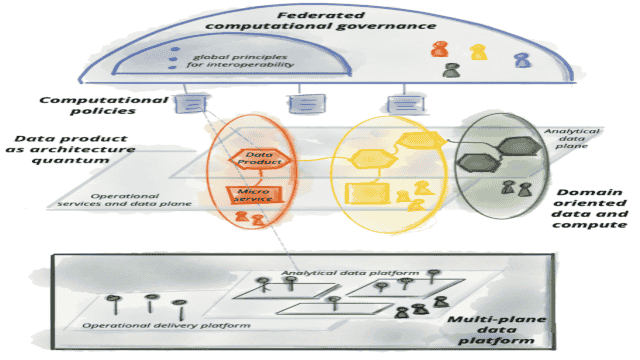
Le maillage de données est un autre concept populaire qui prend de l’ampleur dans les cercles de données. Le maillage de données présente certaines similitudes avec le concept de tissu de données, notamment le désir de mettre fin aux maux de tête sans fin liés à l’existence de normes très différentes en matière d’accès aux données, de qualité, de sécurité, en particulier lors du transfert de données entre les entrepôts de données et les lacs de données.
Mais il y a aussi des différences importantes. Pour commencer, le concept de maillage de données est principalement axé sur la possibilité de permettre à des équipes de développeurs indépendantes de travailler de manière décentralisée, bien que réunies par certains principes généraux. Le tissu de données, en revanche, est plus centré sur la technologie.
Le concept de maillage de données a été initié par Zhamak Dehghani, qui a exposé bon nombre de ses idées dans un article de mai 2019 intitulé “Comment passer d’un lac de données monolithique à un maillage de données distribué”.
L’idée clé de Dehghani était que les ingénieurs de données ne peuvent pas intégrer la transformation des données dans la technologie. Au lieu de cela, elle pensait que la transformation des données devrait être un type de filtre appliqué sur un ensemble commun de données disponible pour tous les utilisateurs.
Ainsi, au lieu de construire des pipelines de données ETL fragiles et voués à l’échec, dans un maillage de données, les données sont conservées dans leur forme approximative d’origine, tandis qu’une série d’équipes spécifiques au domaine s’approprient leurs données lorsqu’elles développent des produits de données à utiliser par l’entreprise.
Le rôle d’IBM i dans les maillages et les tissus de données
Les entreprises qui utilisent IBM i conservent souvent certaines des données les plus précieuses et sensibles sur leur serveur IBM i. Même si les entreprises n’exécutent généralement pas d’analyses ou d’apprentissage automatique sur la plateforme, le système est tout de même familier de l’ETL et de la nécessité d’intégrer les données de manière robuste.
A cet égard, le serveur IBM i a certainement un rôle à jouer dans la nouvelle génération de tissus de données et de maillages de données en cours de conception. Les racines du tissu de données dans l’ETL et la sécurité des données rendent la connexion avec IBM i plus évidente.
En d’autres termes, en étant un peu plus décisif et intentionnel quant à la nécessité de créer des points de contrôle dans tous les systèmes contenant des silos de données, y compris des silos extrêmement importants comme la base de données Db2 for i, le tissu de données et IBM i ont un avenir clair ensemble.
Pour l’instant, les opportunités d’IBM i dans le maillage de données sont moins évidentes. Les professionnels d’IBM i ne cherchent pas, pour la plupart, à trouver leur place au milieu du désordre des lacs de données. Leur rôle est clair : faire fonctionner les systèmes transactionnels de la manière la plus efficace, sûre et sécurisée possible.
Il n’y a pas beaucoup de preuves que les professionnels d’IBM i expérimentent largement la création de produits de données à ce stade. Bien que viendra le moment où les entreprises travaillant avec IBM i pourront explorer le potentiel des données Db2 for i au sein de nombreux cas d’utilisation numériques créatifs, ce n’est pas encore à l’esprit de la plupart des directeurs informatiques, ce qui fait du maillage de données une solution à un problème qui n’existe pas encore – du moins pas encore.